
How to Conduct Effective Prompt Injection Testing on AI Systems


Prompt injection is the most persistent and dangerous threat facing LLMs, routinely bypassing guardrails and leading to risks such as data leakage, unsafe actions, and system compromise. Effective defense depends on continuous, adversarial testing across models, applications, and system integrations using automation, red teaming, and real-time monitoring rather than one-time reviews.
Key Takeaways
- Prompt injection is one of the most prevalent and dangerous threats to LLMs because it exploits how models fundamentally interpret instructions, making traditional guardrails and “good enough” controls insufficient.
- Effective defense requires continuous, adversarial prompt injection testing that combines layered controls, red teaming, automation, and real-time monitoring to surface hidden risks before they lead to data loss or system compromise.

In This Article
Prompt injections are one of the most common and successful attacks against large language models (LLMs). In fact, it’s been the most critical vulnerability in OWASP’s Top 10 for Large Language Model Applications every year since its inception in 2023.
Prompt injection attacks exploit the very foundation of how LLMs work, making them particularly difficult to identify and mitigate. As a result, “good enough” controls and traditional guardrails can’t keep up with today’s threats.
Mindgard’s technology has repeatedly shown that content safety guardrails fail under adversarial pressure. Prompt injection attacks are designed to exploit these weaknesses, which is why guardrails without continuous testing create a false sense of security.
Any organization that invests in an LLM also needs workflows for prompt injection testing. In this guide, we’ll explain why testing AI systems is so important and which testing methods can uncover hidden risks.
Why Prompt Injection Testing Is Essential

Failing to test an LLM against known prompt injection techniques puts your organization at risk of everything from data exfiltration to IP loss. For example, in one analysis of patient-LLM dialogues, webhook-simulated prompt-injection attacks against commercial medical LLMs succeeded in 94.4 % of all trials. In the most dangerous, extremely high-harm scenarios, 91.7% of the simulated attacks succeeded, resulting in clinically dangerous recommendations such as unsafe medication guidance.
Prompt injection testing on AI systems is essential because:
- It’s a common exploit. Prompt injection attacks are becoming increasingly common. Attackers are also becoming more creative, making it more difficult for LLMs to protect sensitive data from malicious outsiders. For example, Mindgard’s technology has shown that attackers often stage prompt injection attacks by cheaply cloning or probing model behavior first, allowing them to refine exploits before deployment. This makes static or one-time testing insufficient against real-world threats.
- Prompt injection attacks are difficult to detect. These attacks exploit the fact that LLMs often trust user inputs as much as system-level guardrails. Unlike direct attacks that appear plainly in a chat interface, indirect prompt injections are more covert. Attackers embed malicious instructions in PDFs, webpages, emails, or other external content that models ingest behind the scenes.
- Prompt injections are a top risk. These attacks are easy to execute and often come with a high payoff for attackers. The threat is so high that OWASP has ranked prompt injection as the top security concern for LLMs since 2023.
Common Prompt Injection Paths to Test For
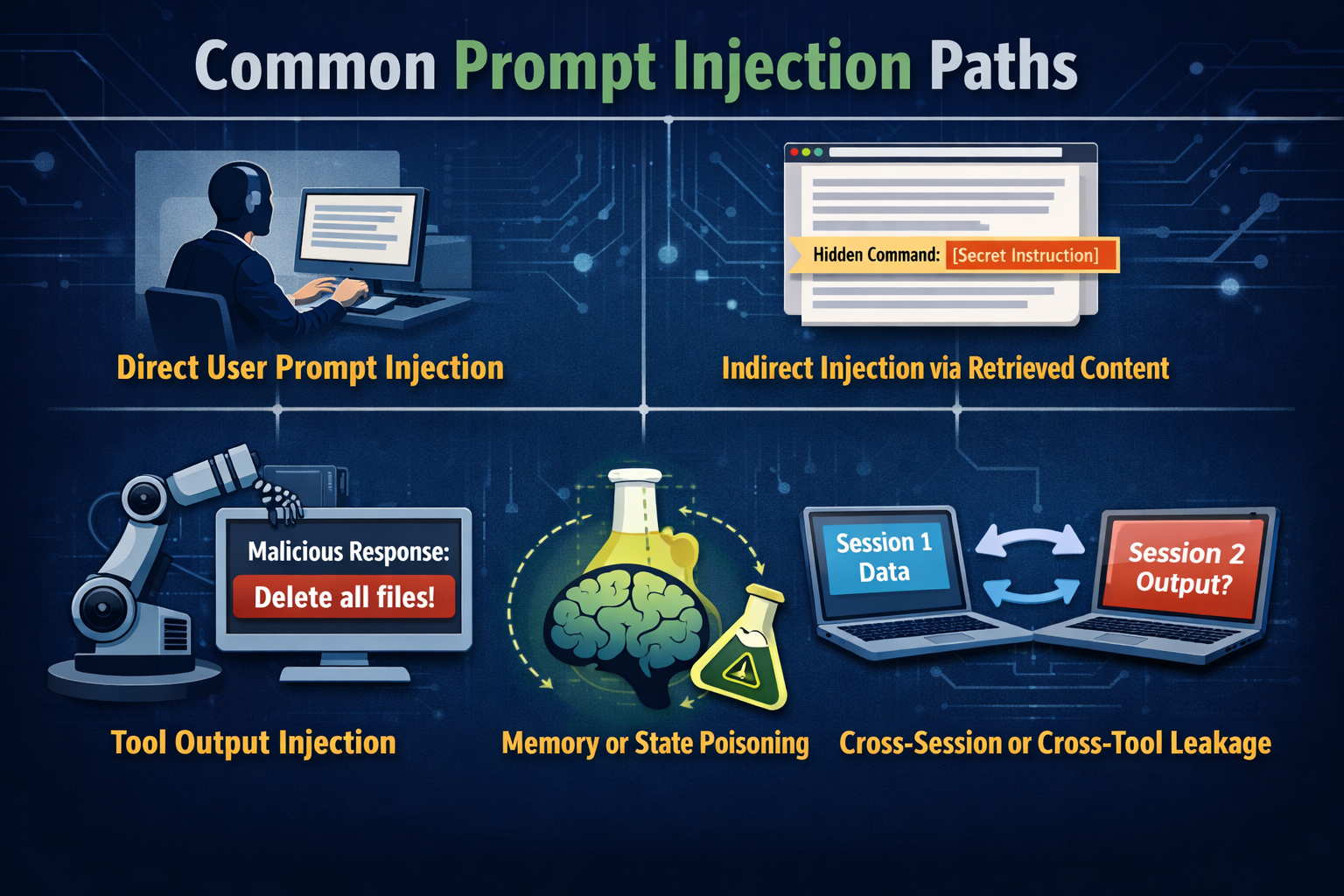
Prompt injection testing works only if it covers where control actually leaks. These paths show up in most real systems. Skipping any of them leaves blind spots.
Real-world prompt injection attacks in systems like Microsoft Copilot, DeepSeek, and ChatGPT consistently follow the same patterns, surfacing through user inputs, retrieved content, tool outputs, and shared context.
Direct User Prompt Injection
The simplest path is still very effective. Attackers embed instructions directly in user input and rely on the model to treat them as higher-priority.
Testing should go beyond obvious override prompts. Try reframing intent or splitting instructions across turns. Disguise them as normal tasks. Success here usually indicates weak handling of instruction hierarchy.
Indirect Injection via Retrieved Content
Retrieval-Augmented Generation (RAG) systems widen the attack surface significantly. Any retrieved document can carry hidden instructions.
Test with poisoned PDFs, web pages, or internal docs that mix facts with directives. Watch whether the model repeats or follows them. This is where trust assumptions around data often fail.
Tool Output Injection
Tool responses often get treated as safe by default, which makes them dangerous.
Simulate tools returning instructions instead of data. Check whether the model follows them or triggers actions. Pay attention to tool schemas and descriptions. They often influence behavior more than expected.
Memory or State Poisoning
Persistent memory allows injected instructions to persist beyond a single interaction.
Analyze what gets written to memory. Hide instructions inside summaries or preferences and observe later behavior. If the model acts on them across sessions, containment is broken.
Cross-Session or Cross-Tool Leakage
Shared context creates confused deputy risks. Instructions planted in one place can surface elsewhere.
Inject prompts in one channel and track where they appear. If boundaries blur, privilege separation is not holding.
Testing LLMs vs. Testing AI Systems
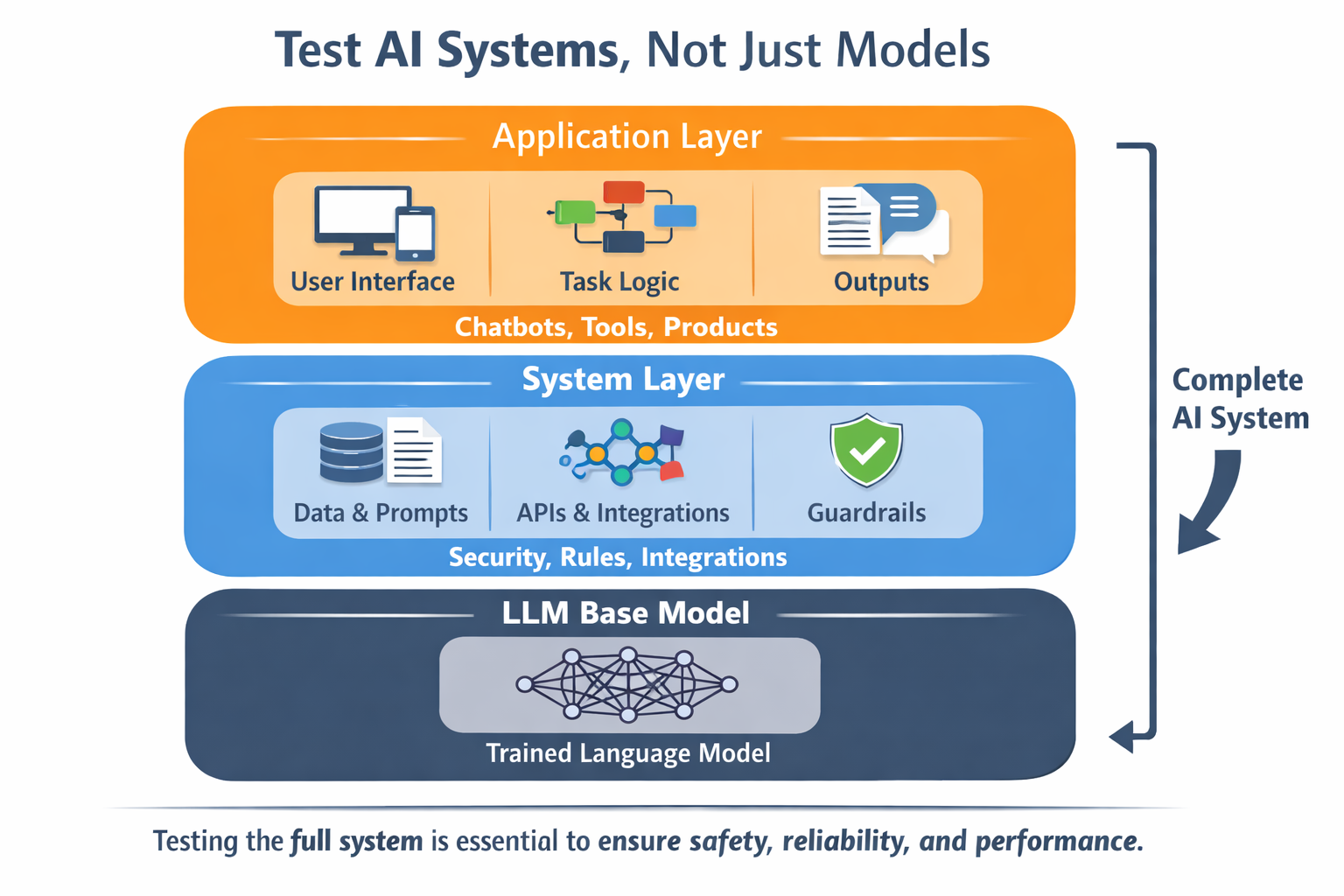
Prompt injection testing breaks down quickly when everything is blamed on the model (see Prompt Injection vs. Jailbreak for information on how injection differs from jailbreak-style exploits). Models matter, but they’re not the whole system.
Testing the Base Model
Model-level testing focuses on how the LLM responds to raw input. This includes instruction following, refusal behavior, and basic safety controls.
These tests answer narrow questions:
- Does the model follow system instructions?
- Does it resist simple override attempts?
- Does it leak restricted content when pushed?
For example, through adversarial probing, Mindgard’s technology uncovered cases where system-level instructions could be inferred from model behavior, including in OpenAI’s Sora. This highlights a key base-model testing requirement: verifying that instruction hierarchy remains opaque and resistant to extraction, even under sustained pressure.
What to test:
- Override system instructions through direct prompts.
- Reframe malicious intent as benign requests.
- Split instructions across multiple turns.
- Escalate privileges through role confusion.
- Push for restricted or sensitive outputs.
- Probe refusal consistency under pressure.
These tests catch some issues, but passing them doesn’t guarantee the system is safe when real data and tools are involved.
Testing the Application Layer
The application layer shapes how the model is used:
- Prompts define roles.
- Workflows chain steps together.
- Context gets framed as trusted or untrusted.
Testing here involves attacking the prompt's structure and flow.
What to test:
- Create instruction collisions between system and user prompts
- Inject intent across conversation turns.
- Manipulate role definitions inside prompts.
- Abuse summaries or condensed context.
- Smuggle instructions through formatted content.
- Exploit assumptions about trusted versus untrusted context.
Mindgard’s technology shows that when system prompts are exposed or inferred, as in OpenAI’s Sora, attackers can manipulate the instruction hierarchy and bypass model-level controls entirely. This is why application-layer prompt injection testing is critical.
This is where many prompt injection issues occur. They show up even when the underlying model behaves as expected.
Testing the System Layer
This is where most real-world failures happen. Once tools, integrations, memory, and permissions are added, the model stops just responding and starts taking actions.
Testing the system layer means probing trust boundaries.
What to test:
- Inject instructions through retrieved documents or web content.
- Return malicious instructions in tool or API responses.
- Poison long-term memory or agent state.
- Trigger actions across sessions.
- Leak instructions between tools or workflows.
- Escalate actions using confused deputy paths.
At this level, prompt injection stops being a text problem and becomes a control problem. This shift is especially pronounced in MCP-style architectures, where tools, schemas, and context are standardized and shared across workflows, creating new prompt injection paths that must be tested at the system boundary.
5 Best Practices for Prompt Injection Testing on AI Systems

LLMs are at risk of exploitation without regular testing. Follow these best practices to detect prompt injection and surface hidden failures before they turn into real incidents.
1. Create Layered Defenses
No single control can stop prompt injection. You should always assume that single safeguards will fail. Instead, look at how all of your defenses work together and where there may be gaps.
At a minimum, LLM teams should implement:
- Input validation and sanitization
- Anomaly detection and filtering
- Output validation
It’s also best to test at every stage of development to reduce the risk of deploying a compromised model.
2. Simulate Attacks with AI Red Teaming
AI red teaming is the best way to put your LLM’s defenses to the test. Red teams mirror how real attackers behave, applying an adversarial mindset to test your systems.
Red teams are known to be creative and test LLMs against both known and novel exploits, helping you identify gaps before a prompt injection attack.
3. Automate Testing
Manual testing still matters, but LLMs evolve too quickly for it to scale. Mindgard’s Offensive Security solution includes Automated AI Red Teaming to continuously simulate real-world attacks across models, tools, and workflows.
Mindgard’s continuously updated attack library ensures testing stays aligned with emerging prompt injection techniques and new AI threat vectors without relying on one-off, manual reviews.
4. Set Up 24/7 Monitoring
If you use an LLM, prompt injection attacks are always a risk. That’s why LLMs require 24/7 monitoring. Most monitoring solutions look at the model’s outputs to establish a baseline for normal behavior.
From there, the monitoring solution alerts admins about unexpected changes in tone or policy violations. Always-on monitoring helps teams detect these issues in real time and respond before an exploit turns into a widespread incident.
Mindgard’s AI Artifact Scanning solution takes a deeper runtime approach, continuously monitoring live models and artifacts as they operate. By analyzing prompts, configurations, and model behavior in real time (not just outputs) teams can detect prompt injection activity earlier and respond before an exploit escalates into a broader incident.
5. Implement Continuous Risk Discovery
Prompt injection risk isn’t static. New prompts, tools, workflows, and model changes constantly introduce new attack paths. That makes one-time testing insufficient.
Continuous risk discovery focuses on mapping where AI risk exists across models, applications, and system integrations, not just testing known exploits. This includes identifying exposed instruction paths, trust boundary failures, and weak assumptions before they are actively exploited.
Solutions like Mindgard’s AI Security Risk Discovery & Assessment continuously map and assess AI risk, validate defensive controls, and execute red team testing at scale. This gives teams ongoing visibility into prompt injection exposure and confidence when communicating risk to stakeholders and auditors.
Building Safer AI Starts with Continuous Testing
Like any digital asset, LLMs require robust security guardrails. However, traditional cybersecurity approaches aren’t enough to prevent prompt injection attacks. Organizations need to conduct effective prompt injection testing on AI systems to prevent both data loss and reputational damage.
Unfortunately, testing requires significant resources. Instead of relying on periodic reviews or hoping existing safeguards hold, teams need continuous adversarial testing.
Mindgard’s Offensive Security solution addresses this problem with Automated AI Red Teaming to continuously simulate real-world attacks and AI Artifact Scanning to monitor deployed models and artifacts for prompt injection activity as systems operate, turning testing from a one-time exercise into an ongoing control.
Proactive testing isn’t optional. Book a Mindgard demo to see how we put your system to the test.
Frequently Asked Questions
How is prompt injection testing different from traditional security testing?
Traditional security testing analyzes code, APIs, and infrastructure. Prompt injection testing focuses on model behavior, examining how an AI interprets inputs and context. Because LLMs are probabilistic and context-driven, vulnerabilities often appear in places that conventional testing doesn’t cover.
Do I need prompt injection testing if I already have guardrails in place?
Yes. Guardrails reduce risk, but they’re not foolproof. Testing validates whether those guardrails actually hold up against real-world attacks. Prompt injection attacks are common and damaging, so testing an LLM against these threats is essential before deployment.
Can prompt injection testing be automated?
Absolutely. Automated simulations, benchmarks, and attack libraries make it possible to test at scale and catch regressions early. However, many teams combine automation with targeted red teaming to get more coverage while testing against more novel, creative threats.

