


Key Takeaways
- LLMs Should Be Treated Like Untrusted Users: Designing systems with LLMs at the center assumes they’re trustworthy, but developers should treat them as potentially malicious users to mitigate risks effectively.
- Proactive Security Design is Critical: Relying on retrofitting security or external safeguards like firewalls is insufficient; secure LLM applications must be built with robust control mechanisms and safety-first architectures from the start.
- Adopt and Adapt Best Practices: Frameworks like OWASP LLM Top 10 provide evolving guidelines to help developers anticipate risks and implement safer LLM-enabled systems, ensuring long-term resilience against emerging threats.
Product development teams far and wide are succumbing to the overwhelming temptation to sprinkle some LLM magic into their applications. But do they understand the unique security risks of LLMs, and are they designing their applications to give themselves the best chance of success?
After spending quite a bit of time in the space, existing system designs I’ve seen place LLM at the heart of the application. When asked for a simple diagram for “an agentic, LLM-based webapp with tool calls to internal services” gemini-2.0-flash-exp generates something like the following [adaped with example tool calls]:

A Google search for “llm agentic application reference architecture” reveals a whole host of similar looking images. I highlighted the LLM in yellow:

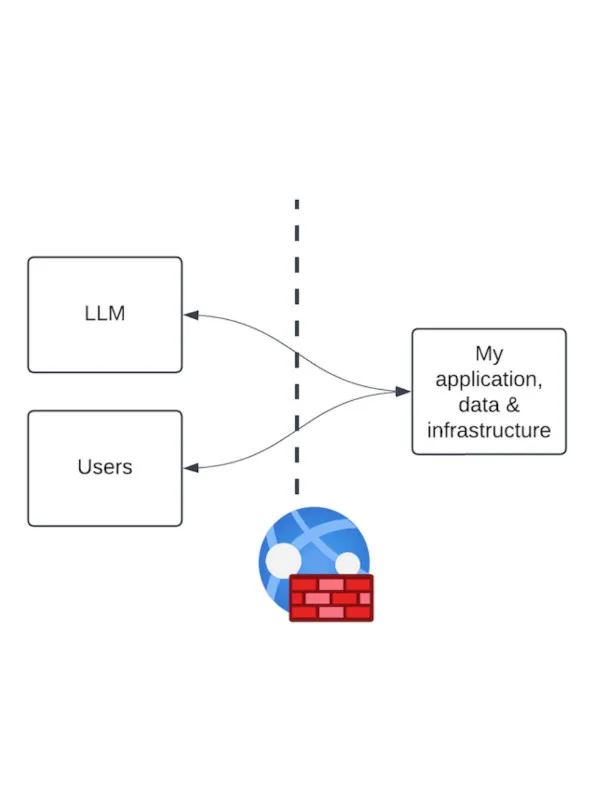
Most of the architecture diagrams put the LLM logically in the middle, where the components feel safer as they're harder to get to. A simplified consolidation of these architectures may look something like this:

The current crop of integration patterns, tools and frameworks — at least those I have come across — double down on the notion of putting the LLM right in the center of the application and further encourage agency for the LLM. For example, Langchain’s how-to guides provide good examples of this: giving the LLM access to internal business logic is near-enough a couple of lines of code.
While these approaches begin to pervade, we are starting to see a crop of issues that lean on one key statement "... the AI service was 'trusted' internally".
I believe that we will start to see a shift toward a world where we’ll hear more of "But why? You should never do that." We will begin to build systems with the understanding that the LLM's output will get compromised at some point. Questioning our approach in this way will lead us to treat the LLM more akin to a user when designing our systems and services.
The Risks
LLMs aren’t just like users, they are users. Ok - that is probably a stretch, but a system that has been trained on mountains of data created by human language, and whose primary purpose is to behave like people from the Internet might be forgiven for behaving like people from the internet. This is further compounded where the LLM is instructed as an agent to perform some form of request action, just like a user of a system would. We needn’t dwell on the dangers of the internet for too long. While we can discourage – i.e. train, prompt – this ‘user’ against a certain behavior, we should assume that it will be coerced away from our intent at some point (or, more simply, slip up).
With the assumption of LLMs as users in mind, we can reconsider the diagram above; this time the LLM is replaced with an internet user:
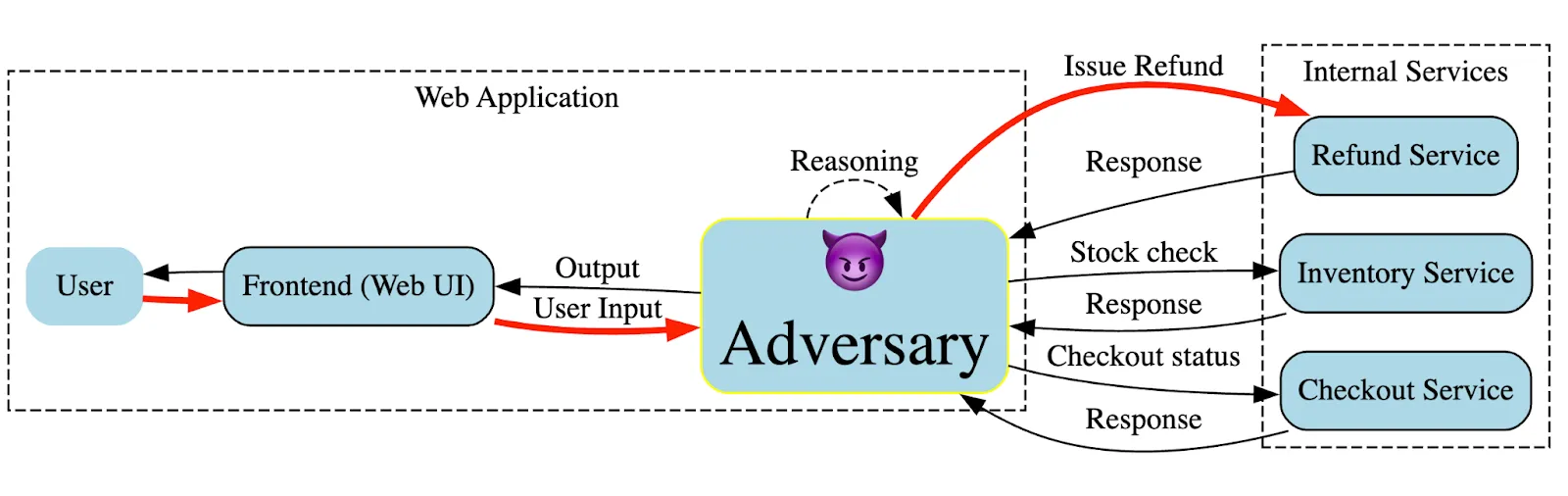
With the frontend, WAF and LLM out the way, the adversary is now in a position to directly issue refunds and potentially hidden from the view of application logs. Put another way, in the web-application’s walled garden, with contextual guards and authorization requirements lowered, our backend refund service is directly opposed to the adversary.
Are we still happy to ship our product? Do we remain confident in our architecture?
This is, again, a little dramatic, but I want to highlight the point that you wouldn’t build an application without considering SQL injection and wait for pen-testing (or the ICO) to tell you about it. You don’t rely on a WAF to protect you against SQL injection and XSS, you design your system with these in mind and adopt patterns, frameworks and practices to mitigate these risks up front.
For those that neglect to consider the implications of their LLMs’ access to data and infrastructure, the problems will start arising. Automated attacks and malware will start attempting to disrupt LLM-enabled systems and like traditional security, preying on those that haven’t kept up to date and thought about their system design.
For a 40 minute exploration of this topic with real examples check out Embrace The Red's real-world exploits and mitigations in LLM applications:
Do we start with ‘best practices’?
Even in the traditional security world, this term can stifle and mislead: who decides what ‘best’ is? Maybe I have found a ‘better’? Does this practice have any relevance for my stack?
But as new technologies become more pervasive, there is a tendency towards a common understanding of safe(r) usage patterns. These ideas and techniques themselves become documented and shared across the industry. They allow you to focus on the specific challenges of your application and domain, and avoid repeating bulky solutions to problems we all share.
In the world of LLM applications, we have started to ask the very same questions. From a security perspective, Mitre ATLAS and OWASP LLM Top 10 talk about the techniques and help us to understand what and why of risks. They provide us with helpful recommendations and a framework with which we judge and reason with designs and implementations. The recommendations laid out in OWASP LLM Top 10 might serve as a helpful checklist before shipping our product/change to production. It is worth mentioning that these frameworks are constantly evolving based on community understanding, particularly for OWASP whereby the techniques described are increasingly specific in the type of risks to address.

Take a look at the image above from the OWASP LLM Top 10’s Example LLM application - conveniently, notice how the LLM is right in the middle. Not in the client/malicious actor bubble!
To hand-select and simplify a few from the dozens of recommendations, we anticipate best-practices to begin including:
- Human-in-the-loop service design - allowing users to validate interactions- both from back-office and end user. I personally see this as critical for ongoing validation of the behaviour of the system - as new threats and idiosyncratic behaviours emerge, humans will become an essential collaborator. The challenge of implementing this is around process and UX: we are still learning how these interactions will work in practice. Additionally, I don’t expect this to be a static target, as people's trust levels inevitably change over time (imagine being asked the 100th time if this action is ok, the reactive ‘yes’ can creep in).
- Rigorous control mechanisms around integrations - if we remove the assumption of a well-behaved LLM, API calls and database interactions will come under greater scrutiny and control. Picking on our example above, the Issue Refund call would likely require us to accumulate the context of user, machine and possibly even data provenance to accurately authorize the request. For example, a bad database entry being given to LLM to silently instruct it to issue refunds (this is an example of Indirect Prompt Injection).
The overriding point here though, is that we now have some guidelines to follow while designing and developing our LLM-enabled applications. We can begin with safety and security in mind and keep our users and ourselves better protected from harm.
Reality
The reality is often one of pressure: pressure to deliver the feature, pressure to stay ahead of the competition. Over time, prototypes and demos become production applications, production applications shapeshift away from their original purposes. Even seemingly clairvoyant teams find their original design assumptions invalidated and through a series of innocent incremental changes and unexpected usages.
Getting a first prototype up and running might see us reach for off the shelf frameworks and examples; this is a rational place to start, especially if we’re feeling new to the technology and practices. Following the how-to found earlier, we implement our first prototype to look something like:
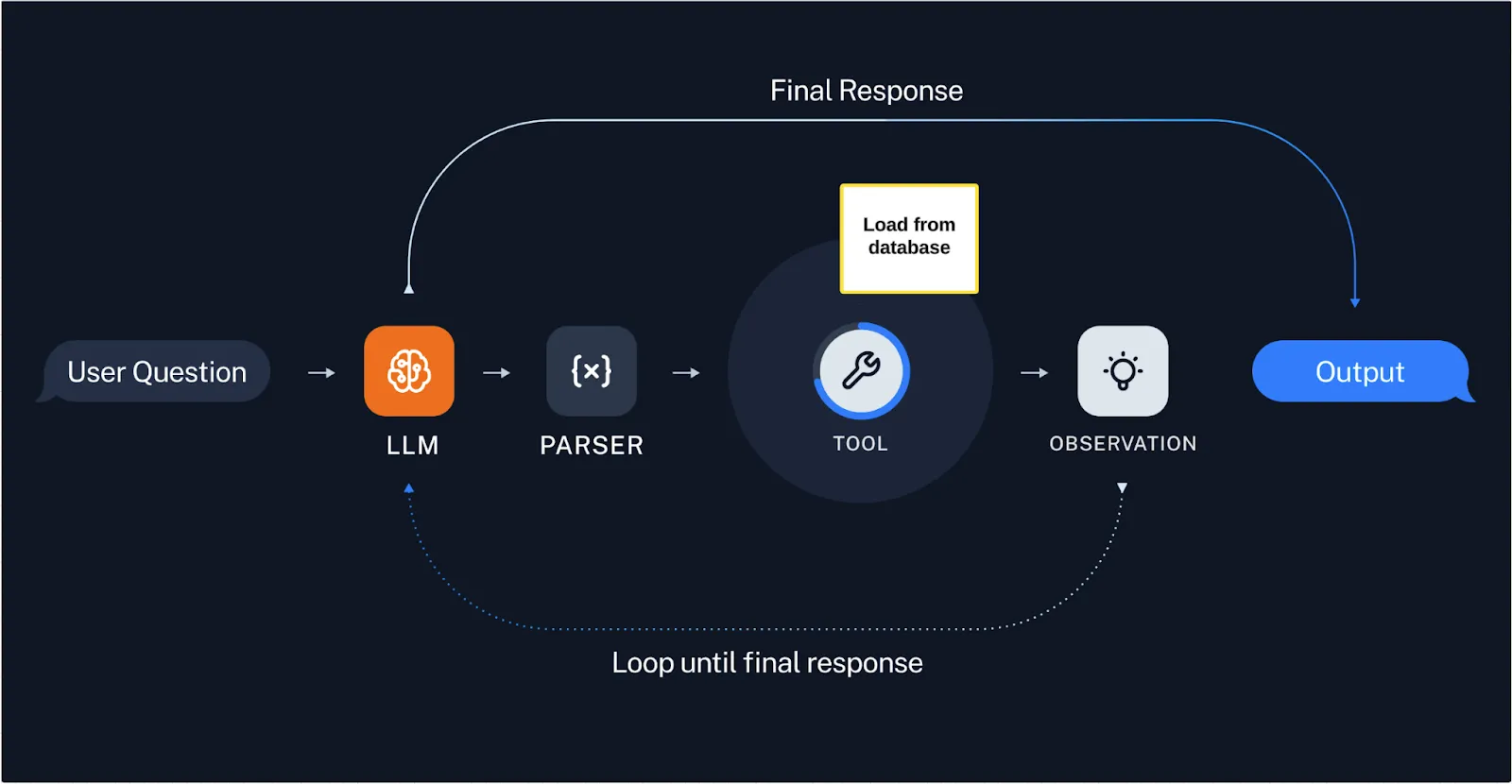
This looks familiar - our chosen design has the LLM right in the centre of our system. While our user question flows through existing firewalls and protections, output of our LLM is directly accessing internal services. In our first iterations we might even find this a safe option due to simplicity or usage constraints.
As time passes, however, there is a certain inevitability that we will start to enable more features. The reality is that teams will feel pressure to deliver. The complexity grows and the original design assumptions begin to waiver.
Referring back to our inferred best practices, we quickly realize that the frameworks and tools we’ve leveraged, indeed the overall architecture will take a serious amount of wrangling to achieve our security goals.
Can we retrofit some solutions? Absolutely. But the idea that we’d now retrospectively apply all the recommendations in our now slightly dusty OWASP manual is possibly a bit unrealistic now - what features must I sacrifice? And which components need complete redesign? These are not questions anyone wants to answer.
Too gloomy?
As a hardened skeptic from years of designing and building systems, I have a natural inclination towards considering this an existential problem for LLM applications. But I don’t think this is the case.
Firstly, the threat is still emerging. Given risk is a part of doing any business, as long as we can measure our risks and respond to emerging threats, the question now becomes what and how much risk is acceptable for my application use case. While the early adopters of LLM applications painstakingly try to figure this out, the industry’s notion of best design practices will evolve too, and for the benefit of us all.
Greater support for firewall and safety controls between the LLM and our applications will emerge. Output from LLMs will be tracked with provenance information to help people and automation determine associated risks. Authorization systems’ design will begin to understand the combined user and assistant context before estimating the safety of an operation. These features will begin to integrate into our go-to tools and frameworks and eventually become second nature.
We will stop thinking about system prompt as a guardrail for systems and more as a guardrail for the user+assistant combination. We will start implementing deterministic controls that assume the LLM will behave in mysterious or malicious ways. Requests from LLMs will pass through controls similar to those for user requests.
More subtly, our LLMs will begin to occupy a space on our logical architecture diagrams closer to our users. Even though that is unlikely to become a physical reality, it will encourage us to think carefully about where and how to apply trust.
Think of this as a threat model with a trust boundary either side of the LLM, like you would with a user, and then follow the implications for secure design.
Our simplified and consolidated architecture starts to look more like this:

Testing the security of these AI systems will involve some new and complex challenges. We have new trust boundaries to consider, new user attitudes and novel system weaknesses. Penetration testing and red teaming will become an essential tool to help identify design issues and, importantly, give us realistic impressions of weaknesses and provide the foundation for effective business risk calculations.
Conclusions
I look forward to a future where our go-to tools and frameworks and design patterns have safe design at their forefront, to let us focus on delivering the best possible experiences to our users. In the meantime, I hope this provides some useful food for thought on design and threat modelling considerations when working with LLMs.

