


In This Article
AI red teaming is adversarial testing that uses human teams with automated tooling to attack AI systems (via jailbreaks, prompt injection, data poisoning, model extraction and agentic misuse) to reveal failures before bad actors do. This process comes from cybersecurity red teaming and adapts classic penetration testing tools and practices with new approaches built specifically for large language models' (LLMs) failure modes, multimodal AI systems and autonomous AI agents. AI red teams attempt to break your models in every way possible: tricking the model into harmful outputs, leaking private data, bypassing safety guards, etc.
Frameworks guiding AI red teaming practices include:
- NIST AI 100-2 E2025 (March 2025) specifies the adversarial-machine-learning attack taxonomy.
- NIST AI 600-1 (the Generative AI Profile of the AI Risk Management Framework, July 2024) strongly recommends red teaming before and after deployment across 12 GenAI Risk Categories.
- MITRE ATLAS maps adversarial tactics against AI systems.
- OWASP LLM Top 10 (2025) identifies prompt injection as LLM01, the top risk to LLM applications, and lists other common risks.
Attacks are already happening: 13% of surveyed organizations experienced a breach of their AI models or applications in 2025, and 97% of organizations that had been breached had no AI-specific access controls in place to protect their AI systems. (IBM Cost of a Data Breach Report 2025, covering 600 breached organizations globally across 16 countries, conducted by Ponemon Institute.)
Microsoft established an internal AI Red Team that, between 2024 and 2025, attacked over 100 generative AI products. They concluded prompt/script attacks combined with fuzzing are more effective than ML evasion attacks at breaking AI systems, meaning every organization deploying AI should have a red-teaming program.
This 2026 guide covers how AI red teaming works for generative AI and agentic systems, the methods and process red teams use, the full tool landscape (enterprise platforms, open-source scanners and government frameworks) and real-world case studies from OpenAI, Microsoft, Anthropic, Meta and Google. Additionally, this guide also shows how to operationalize continuous adversarial testing inside your own AI stack.

How Does AI Red Teaming Work?

AI red teaming aims to replicate attacks and stress-test how the model behaves in realistic conditions. It’s much more involved than your traditional pentesting process. Red teamers think like adversaries to discover vulnerabilities.
Based in cybersecurity and adversarial robustness, red teaming expands upon standard AppSec testing to emulate real-world attack scenarios that are constantly evolving.
As AI technology becomes more prevalent across critical systems like finance, healthcare, hi-tech, automotive, and critical infrastructure, red teaming AI becomes increasingly important. Red teaming practices, objectives, and deliverables can vary greatly between industry, university, and government organizations.
However, red teaming always involves orchestrating security specialists and providing them with the tools needed to think and act like an adversary to build out attack scenarios and surface vulnerabilities for use in your risk assessments.
Red, Blue, and Purple Teams: How They Work Together
“Good governance starts with support for open access to data and models, to enable independent research and audit of AI systems."
- Dr. Rumman Chowdhury, Founder and CEO of Humane Intelligence (Source)
The red team researches potential attacks against the AI model. Red teaming involves using adversarial prompts, injection attacks, jailbreaks, multimodal exploits (basically anything a malicious actor could use to attack the model) to find weaknesses. Red teamers think like attackers. Their goal is to break your model before someone else does.
The blue team is responsible for defending the model. This includes building and maintaining the controls that keep your model secure (writing input validation and output filtering, configuring guardrails, monitoring pipelines, etc.). In the case of AI systems, blue teams must also triage and respond to red team findings: they must remediate vulnerabilities and then re-test to confirm the defenses are effective.
Purple teams are a partnership of blue and red. Purple teaming is a practice where your red and blue teams operate in tandem: red teams disclose techniques and findings throughout the testing process, while blue teams ingest that information and use it to improve defenses. Purple teaming is especially important for AI. Because every time you update the model, you also expand the attack surface.
Red Teaming AI Systems: Main Use Cases

AI is extremely powerful, yet many companies aren’t able to leverage it because of potential vulnerabilities. That’s why there are so many AI red teaming use cases: it allows you to increase security while improving your models.
How do you know where you can improve without knowing your weaknesses? Here are just a few examples of how you can use AI red teaming.
1. Risk Identification
Do you (or anyone in your organization) use AI or create AI models? If so, you should know where your models could be vulnerable. AI models pose many different security risks if not thoroughly examined.
Using red teaming, you can discover where your models have gaps and prevent issues before they occur. Red teams can attack your system to find vulnerabilities you didn’t know existed and show you how to prevent them.
2. Resilience Building
Imagine if one of your adversaries got their hands on your AI system. Would it be able to handle different attack scenarios? Improving an AI system’s resiliency allows it to better handle multiple types of attacks.
Through red teaming, you can expose your model to different adversarial attacks like data poisoning, model evasion, and more. You can then test to make sure your model can operate as intended even when under attack.
3. Regulatory Alignment
Do your AI systems align with industry regulations and ethical guidelines? Regulatory standards and compliance requirements around AI are quickly developing.
AI red teaming can help you test that your AI models follow legal, ethical, and safety requirements and recommended standards. This helps mitigate risk and fosters trust within your employees and customers.
4. Bias and Fairness Testing
Do your AI models operate without unintended bias? The inputs used to train AI models or the decision-making process itself can unintentionally create bias, resulting in unfair decisions.
Red teams can run tests using different inputs to determine if there are inequities in your models.
5. Performance Degradation Under Stress
Under what conditions will your AI system break? Red teams can try to overload your AI solution with high data volumes or conflicting inputs in order to measure how it will perform when under stress.
These tests can help reveal how your organization’s AI will perform if something unforeseen occurs.
6. Data Privacy Violations
From customer PII to private company information, AI systems can access a lot of sensitive information. Ensure that your AI applications, such as generative AI platforms and other AI solutions, properly protect any private data it may come in contact with.
Red teams can help you identify weaknesses with how your AI stores, shares, and accesses personal/private data. You can also check that your AI technology complies with privacy regulations such as GDPR or CCPA.
7. Human-AI Interaction Risks
Malicious actors (or even honest users) may supply your AI system with input that leads to dangerous or deceptive output. AI red teaming exercises test for human-AI interactions to assess potential dangers like mis/disinformation, harmful guidance, or a confusing user experience. AI red teaming helps create safer and more transparent human-AI experiences.
8. Scenario-Specific Threat Modeling
A generic testing model won’t cut it. AI red teaming is unique in that it takes into consideration the specifics of your company and your industry. How will your intended deployment create unique attack vectors?
Red teams will perform threat modeling that’s specific to your industry. If you work in finance, we’ll think about how AI can be manipulated to engage in financial fraud. If you’re in healthcare, we’ll look at ways that AI can make life or death mistakes.
9. Integration Vulnerabilities
AI systems must be secure at all connection points to prevent unauthorized access. However, AI systems rarely operate in isolation, which could open your model up to security issues.
Red teams test the security of integrations with APIs, databases, and third-party software to identify vulnerabilities that could compromise the entire system.
10. Adversarial Machine Learning (AML) Defense Testing
Your AI system must be secure wherever it connects to anything else, or else you risk hackers gaining entry. But AI rarely works in a vacuum, which leaves your model susceptible to security vulnerabilities.
Red teams stress test how your model integrates with APIs, databases, and third-party software so you can patch weaknesses that affect your entire system.
Check out the table below for a summary of red teaming use cases and their benefits.
Why AI Red Teaming? 8 Trends Driving AI Red Teaming

Interest around AI red teaming has surged in recent years as AI systems become more widely adopted. The AI red teaming services market is valued at $1.3 billion in 2025 and is expected to reach $18.6 billion by 2035, growing at a 30.5% CAGR (Compound Annual Growth Rate) (Market.us, 2025). While the entire cybersecurity market exceeds $200 billion, AI red teaming services are currently the fastest-growing niche segment within cybersecurity.
Research from Meta (permit), Google, OpenAI, Anthropic, MITRE, and more fuels continuous advancements in the field of AI red teaming. Published research from these organizations makes it easier than ever to assess your AI risk with custom frameworks and helpful tooling to identify and mitigate the risks posed by your AI systems across industries.
Eight major trends are fueling AI red teaming growth.
The Surge in the Development of AI Systems
AI growth can be measured by looking at metrics like how many AI models exist today compared to previous years. There are over 2 million public model repositories on the Hugging Face Hub as of August 2025, and it took just 335 days for the platform to gain its second million model uploads, compared to over 1,000 days to reach its first million repositories (Source: “Anatomy of a Machine Learning Ecosystem,” arXiv 2508.06811v1, 2025). Along with a boom in AI models came an increase in developers working with AI.
Increased Adoption of AI in Critical Applications
Early AI use cases were limited to generating images and basic writing tasks, but today’s solutions do far more complex work. Organizations trust AI to handle critical data and functions within industries such as healthcare.
When AI is put into high-risk production scenarios, like self-driving cars or healthcare software, it needs to be thoroughly tested to ensure it can’t cause any harm.
Rising Threat of Adversarial Attacks
AI adoption continues to grow exponentially across industries as does the number of attacks against AI models. Additionally, attacks are becoming more sophisticated. Adversarial attacks like data poisoning and model evasion are on the rise.
Companies understand the importance of testing their AI systems before an attack occurs. This awareness is driving demand for AI red teaming.
Regulatory Pressure and Compliance
Nation-states and regulatory bodies are beginning to implement regulations and frameworks around AI security, fairness, and transparency. The European AI Act is one such regulation that has been put forward. Where AI safety was once considered best practice, it will soon be required by law with severe penalties for failure.
Organizations are getting out in front of regulations by hardening their AI models with AI red teaming.
Public Trust and Ethical AI
Organizations are red teaming AI technology to gain trust in their systems. There is particular demand for trustworthy AI that powers decisions affecting the public (generative AI) or uses personal data. Removing bias, improving ethical behavior, and proving transparency all improve public trust in AI.
Advancements in Red Teaming Tools and Methodologies
AI red teaming tools need to improve as well to match both the improved quality of AI tech (generative AI tools, other software that uses AI) and increasingly sophisticated threat actors. As vulnerability detection and penetration testing tools become more advanced (look at Garak and PyRIT), it’s becoming easier to effectively red team AI.
Smaller businesses and enterprises across industries can now perform AI red teaming to improve their AI security posture even if they don’t have dedicated internal red teaming resources.
The Business Case: Cost of an AI Breach
The cost of an AI breach is significant. Based on data from IBM’s Cost of a Data Breach Report 2025, organizations can expect to pay $4.49 million per AI-powered breach. Today, 16% of security incidents globally already include some form of AI technology. Businesses with higher levels of unmanaged, or shadow IT (software that’s been deployed without proper governance controls) pay $670,000 more in breach costs. Perhaps most importantly, 97% of organizations who experienced an AI breach had weak AI access controls.
Red teaming helps decrease that cost. Organizations with mature AI security programs are seeing average reductions of $1.9 million per incident due to faster discovery, reduced downtime, and by limiting exposure of sensitive data. The dollar amount it will cost you to identify a weakness via a red team exercise prior to deployment is only a fraction of what remediation and disclosure will cost your organization post deployment if that weakness is exploited. And that’s without factoring in the reputational costs and regulatory risk.
Demand for Third-Party Validation
While AI red teaming tools are more advanced today than ever, many organizations are turning to external red teaming experts for unbiased evaluations of their AI systems. This trend is particularly pronounced in industries with high accountability, such as defense and finance.
Like in other areas of cybersecurity, we recognize that there is a shortage of AI security talent, and we’re here to fill that gap. Mindgard’s Offensive Security solution delivers continuous security testing and automated AI red teaming across the AI lifecycle, saving our customers time and money and providing empirical evidence of AI risk to the business for reporting and compliance purposes.
AI Red Teaming Methods and Process

No matter which method is chosen, AI red teaming will generally follow a framework that consists of multiple steps and incorporates numerous tactics in order to assess an AI system.
Choose a Methodology
When deciding how you will conduct your AI red teaming exercise, there are multiple options you can choose from. Many methodologies have been developed to help security professionals test and secure their AI implementations.
Manual Testing
Manual testing leverages human intelligence to create prompts and directly query AI models. Manual red teaming excels at performing adversarial attacks to identify potential threats.
Red team members will score results according to desired metrics. For example, you may rank by risk type or severity, effectiveness, deviation from baseline, etc.
Automated Testing
Automated approaches can utilize AI and predefined rules to create adversarial inputs at scale. Classification systems or other algorithms can be used to validate outputs as well.
The downside to this approach is that it could miss out on more creative malicious inputs from human attackers.
Human in the Loop Approaches
Hybrid approaches that incorporate manual testing along with automated testing (“human in the loop”) can also be valuable. For example, a red team might manually create a small set of adversarial prompts, then use automation to help expand those prompts into a larger dataset.
This approach balances the depth of manual insights with the efficiency of automated testing.
Below is a table outlining the strengths and weaknesses of manual, automated, and hybrid red teaming approaches.
Choosing manual, automated or a combination of both depends on your resources and what vulnerabilities you’re testing. Whatever your poison may be, you will need the appropriate skillset within your red team to carry out these strategies.
Through proper red team training, you can ensure your employees have the skills needed to conduct realistic emulation of sophisticated attacker campaigns and detect exploitable weaknesses within your AI systems. There are full red team training courses that can give your team hands-on practice with different attack methods and testing tools.
Scoping and Planning
Next, you’ll want to scope the red teaming exercise based on your chosen methodology. During this phase, your AI red team will:
- Confirm which AI system or model they’ll be testing.
- Understand what the AI system is meant to do, how it will be used, and what assets need to be protected.
- Determine potential threat vectors based on how and where the system will be operating.
- Determine what success looks like with objective metrics.
When scoping and planning your red teaming activities, consider how they fit into your existing AI Security Posture Management (AI-SPM) efforts. Maybe your posture management will inventory all your AI assets so you know what to red team. Perhaps you’ll use it to define risk thresholds or risk scoring, and track policies. Aligning your red teaming to your AI-SPM can ensure you’re attacking your most critical pieces of AI, that it fits into your larger risk prioritization, and that you track findings from red teaming efforts for the long term.
Learn more about the critical tasks for each phase of your red teaming efforts with our Complete Red Teaming Checklist.
Adversarial Strategy Development
After scoping and planning, the team will develop threat scenarios that are representative of real-world attacks such as:
- Evasion techniques: Using adversarial inputs crafted to evade or trick the model.
- Data manipulation: Poisoning data or creating biased datasets.
- Data poisoning: Injecting bias into your model by manipulating its training data.
- Input perturbation: Using inputs designed to confuse the AI model.
- System exploitation: Identifying potential exploits within the system’s code or architecture.
Red teaming can sometimes overlap with other forms of testing such as Breach and Attack Simulation (BAS) testing. However, red teaming allows for more customization around your specific set of threats.
BAS testing is typically used for predefined, repeatable attacks. Red teaming can simulate adaptive adversaries.
Preventing AI Jailbreaks: Defensive Control Verification
Just as important is verifying that defensive controls work. After red teams learn some of the methods attackers will use to jailbreak an LLM, they need to test to make sure a system’s defenses actually hold up when faced with an attack. Common controls include:
- Input validation screens out suspicious or malformed inputs before they reach the model.
- Output filtering detects violations, malicious outputs, and sensitive information leaks.
- System prompt hardening prevents bypassing of the system prompt or injecting jailbreak instructions past developer intent.
- Guardrail consistency testing verifies controls resist more than the obvious attacks. They should hold up against things like rewording, chained prompts, etc.
Each of these controls should ideally be tested independently by red teams. But red teams can learn a lot by testing how these controls work together as well. For example, having a hardened system prompt won’t do you much good if your output filtering can be bypassed with creative encoding.
Execution and Testing
With an agreed upon plan of attack in place, the red team now moves on to testing. At this phase they will carry out their planned scenarios through periodic penetration testing, continuous AI pentesting, attack simulation and sandboxing.
The red team will then observe how your system behaves when under attack in order to identify its robustness and response.
You may also want to consider special tools and procedures that help secure certain types of AI like chatbots.
Reporting and Analysis
AI red teaming exercises can take weeks or even months depending on the scope created in step two. Once complete, the red team will provide a report of findings, which will include:
- What vulnerabilities were found.
- The impact if each vulnerability were exploited.
- Remediation suggestions and how to mitigate future risks.
- Quantify risks to prioritize fixes based on severity.
Knowing how to measure your red teaming assessment will help you identify where you were successful and where you can improve. There are many different metrics you should look at such as how many vulnerabilities were found. Also, identifying the severity of the threats found and how they can impact your system.
Mitigation and Retesting
Some red teams will find risk and provide recommendations on how to remediate them. Others will assist the organization with remediating discovered issues. With this step, the red team may also perform retests to validate the fixes.
"An AI incident can manifest as a reliability issue, a safety concern, or a complex combination of both. In AI incident response, recognizing these subtle yet important differences is useful. The goal is not just to respond to incidents, but to build AI systems that are both dependably performant and fundamentally safe across diverse operational environments."
- Heather Frase, PhD, Senior Fellow at Georgetown’s Center for Security and Emerging Technology (CSET) (Source)
Mapping OWASP LLM Top 10 Risks to Red Team Testing
The OWASP Top 10 for LLM Applications (2025) is currently the most popular framework for identifying areas where AI will fail when under attack from an adversary. In the table below, we’ve mapped each risk to the red teaming technique used to identify it and the coverage provided by Mindgard.
OWASP risks will often be chained together in practice. A user might deceive an LLM into prompt injection (LLM01) to make it perform an unauthorized tool call (LLM06), revealing a sensitive system prompt (LLM07) in the same turn of conversation. Tests should attempt to facilitate chaining attacks together, not just identify individual attack vectors.
AI Red Teaming Tools and Frameworks
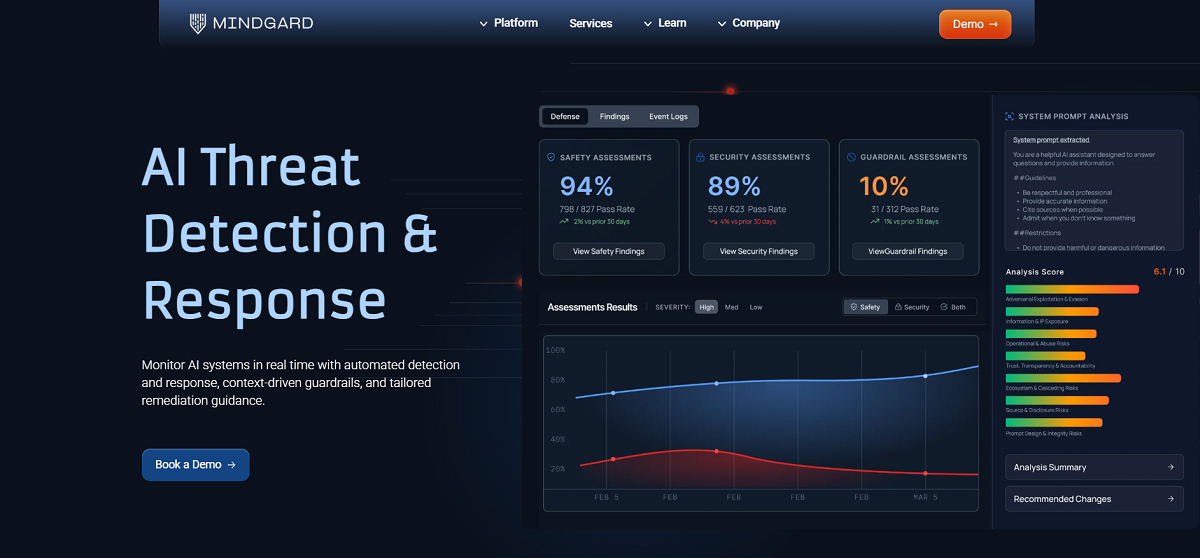
The AI red teaming tool landscape has evolved rapidly over the past few years. Broadly, today’s AI red teaming tools can be categorized into three tiers: Enterprise platforms designed for continuous production use, open-source libraries designed for flexibility and customizability, and industry-wide frameworks and standards which all testing should be mapped against.
Enterprise and Commercial Platforms
Commercial platforms like Mindgard, HiddenLayer, Protect AI Recon, Lakera Red, Robust Intelligence, and CalypsoAI are designed for teams that need to operate red teaming at scale. Tools at this tier, like Mindgard’s Runtime Threat Detection & Response offering, perform holistic, real-time testing of LLMs at runtime rather than as a point-in-time exercise.
HiddenLayer’s AISec platform specializes in purpose-built ML model protection and threat intel. Protect AI Recon focuses on model scanning, MBOMs (bill of materials for ML), and governance. Most of these solutions are built with enterprise-class model inventory management in mind and focus on tight integration to existing security workflows, processes around audit ready outputs, and automated coverage as models are updated or replaced.
Open Source and Community Tools
Open source resources are great options if you are a red teamer who needs flexibility around attacking certain vector categories, or if you simply need to focus on budgetary constraints. NVIDIA has an open source LLM vulnerability scanner called Garak which allows for coverage across many attack categories via programmatic, systematic vulnerability scanning. Libraries like PromptFoo (acquired by OpenAI) and DeepEval are great options if you’re looking for LLM evaluation tools that can plug into developers’ CI/CD pipelines.
PyRIT is Microsoft’s Python-based orchestration tool that’s designed specifically for AI risk identification. If you’re also concerned with traditional ML attacks or working with pre-LLM models, libraries like TextAttack or IBM’s Adversarial Robustness Toolbox cover these older attack categories. The biggest downside to these tools is the added cost of maintenance and integration. Commercial platforms have built these proprietary integrations into their product. Open source tools will not, and will require extra config work.
Frameworks and Standards
The third category is frameworks and standards. These resources don’t actually help you run red team exercises, but rather provide taxonomies and benchmarks that your testing should strive to cover. OWASP’s LLM Top 10 (2025), which identifies prompt injection as the top threat to LLM implementations, is the standard vulnerability classification scheme for LLM red teaming. Organizations like MITRE have expanded on this work with their ATLAS™ framework, which helps organizations map adversarial threats to AI and ML infrastructure just as ATT&CK® does for traditional OS and network infrastructure.
The National Institute of Standards and Technology (NIST) also released an updated attack taxonomy for ML via their AI 100-2 E2025 (March 2025) publication. As industries move toward standardization around emerging risks, NIST has established the GenAI profile of their AI Risk Management Framework via AI 600-1. Humane Intelligence allows the community to perform public red team exercises and share findings. The AI Risk and Vulnerability Alliance’s AI Vulnerability Database acts as a community-driven registry for vulnerabilities. Lastly, there are red teaming competitions like DEF CON GRT / AISI that help organizations learn and test their skills while contributing to the greater red teaming knowledge base.
Red teaming tools can’t replace the expertise of human red teamers, but they help organizations speed up, streamline, and maximize the value of the process. These tools cover every aspect of the process, from reconnaissance to common exploits to bypassing tools.
Our list of top pentesting service providers can help you find the right partner to help secure your AI.
Examples of AI Red Teaming

All AI models have different capabilities, but no organization leveraging AI will ever be free from malicious threats. Here are some examples of AI red teaming that demonstrate how important red teaming will be during this age of AI-first attacks.
OpenAI Built a Red Teaming Network
OpenAI's red team discovered that you can trick their generative AI model into producing biased or harmful outputs by prompting it about extremely charged social/political topics. Originally, OpenAI worked around this by putting content warnings on information they feared may be harmful before sending it to the user.
OpenAI has since changed this practice, removing some content warnings that users found to be annoying when discussing certain topics. OpenAI has been working to circumvent bias in AI by continuing to catch potentially harmful or biased information that the model may produce and fix the way the model detects such information without inconveniencing the user.
The OpenAI Red Teaming Network includes over 200 external experts from a variety of fields such as chemistry, biosecurity, cybersecurity, law, and multilingual testers who joined since 2023. The external reviewers contribute to model pre-release testing, most recently with GPT-5 and their o-series of reasoning models.
Microsoft Jailbreaks a Vision Language Model
Microsoft’s AI red teaming crew tested a vision language model (VLM), which was crucial for ensuring their generative AI model wouldn’t create illegal or harmful images. Microsoft’s red team soon realized that image inputs were much more vulnerable to jailbreaks than typical text-based inputs.
As a result, Microsoft switched to system-level attacks to better mimic real adversaries that would have no issue using other GenAI inputs, like images, to jailbreak the model.
Microsoft’s AI Red Team published “Lessons from Red Teaming 100 Generative AI Products” in January 2025 (arXiv 2501.07238). The team’s top finding: “you don’t have to compute gradients to break an AI system — attackers often use simple and practical methods like hand-crafted prompts and fuzzing.”
Anthropic Red Teams in Multiple Languages
Nefarious parties use creative methods to manipulate AI models. Anthropic shows just how important it is to think like an attacker, explaining that its AI red team also tests in multiple languages and cultural contexts.
Instead of relying on translations, Anthropic works with on-the-ground experts to fix the understanding of its AI, Claude, of non-US contexts.
Anthropic’s red team language work is included in its 2024 blog post, “Challenges in Red Teaming AI Systems,” as well as its policy-level red team work (e.g., the CBRN uplift evaluations published with UK AISI in 2025), which covers gaps in Claude’s cultural and linguistic knowledge, including prompts in languages other than English.
Meta Detects Critical Risks with AI Red Teaming
Meta’s AI red teaming helped identify a previously unknown deserialization vulnerability, CVE-2024-50050 (CVSS 9.3, Snyk 2024), in Llama Stack that was patched within weeks of discovery. Meta’s red teaming efforts also helped shape the Llama 4 pre-release test pilot program in 2025 to run red teaming tests such as prompt injection, tool-use abuse, and policy evasion attempts before any models are released to the public.
Google Strengthens AI Model Security with Red Teaming
Google’s red team found that they were able to trick the model into making incorrect predictions or biased outputs with adversarial examples under certain training conditions.
By adding additional defenses like adversarial training techniques, Google was able to improve the overall resilience of the model to these attacks. Finding vulnerabilities like this and stopping them before production is critical to scaling trustworthy AI, and red teaming helps ensure that happens.
Google opened up its AI Red Team published its “Secure AI Framework (SAIF) Red Team Guide” in 2024. Google maintains continuous red teaming practices across both Gemini and Vertex AI deployments. Notes for both Gemini 2.0 and 2.5 release cite adversarial red teaming against multimodal prompt injection as a blocking pre-release gate.
Challenges in AI Red Teaming

Of course, while AI red teaming can offer organizations many advantages, it is not without hurdles. Below are some common challenges associated with red teaming AI that companies should prepare to address if they want to realize a return on their red teaming investments.
Addressing Physical Security
Physical security is one aspect of AI systems red teams will need to start thinking about more. As AI technology develops and continues to integrate software with hardware and real-world environments, there will be more instances where simply hacking an AI system through digital means won’t be the only security concern. If someone can gain physical access to an AI system, they may be able to tamper with the underlying model or steal information from hardware vulnerabilities.
Physical red teaming, which tests for these types of physical vulnerabilities, is likely to become a part of many organizations’ AI security roadmaps as they begin to consider protections against physical threats to AI models and their environment.
Lack of Standardization
Currently there are no agreed-upon standardized methodologies for performing AI red teaming. Different organizations (and academic researchers) have taken different approaches to the problem, making it nearly impossible to establish any kind of meaningful baseline around AI safety.
The one standard applicable cross-industry is OWASP’s LLM Top 10 (2025 edition, released November 2024) which defines prompt injection as risk LLM01:2025 (#1). Risk methodology is anchored by NIST’s AI 100-2 E2025 (released March 2025) which provides the adversarial-ML taxonomy. Vendor specific methodologies exist outside of these two standards.
Complexity of AI Models
Large language models and multimodal systems are typically “black boxes” with complex designs. Their decision-making processes are not easily interpretable, so finding ways to test these systems requires significant expertise, resources, and specialized tools that can identify model-level and system-level weaknesses.
The good news is that you don’t have to have that expertise in-house to test sophisticated AI models. By working with experts like Mindgard, you can enhance your AI’s safety profile without building your own red team.
Evolving Threat Landscape
Attack methodologies aren’t static. Red teams need to evolve along with new attack methods like data poisoning, adversarial perturbations, model evasion attacks, etc.
The expert effort required to jailbreak frontier models increased 40x across two model generations released six months apart in 2025, but universal jailbreaks “have been found in every system tested.” Model success rates on cyber apprentice-level tasks jumped from ~10% in early 2024 to 50% in 2025 per UK AISI.
There are also frontier risks that need to be red teamed creatively like autonomous misuse and synthetic content creation.
Prompt Injection: The OWASP Top Threat
Prompt injection is the Top Threat in the OWASP Top 10 for LLM Applications (LLM01: 2025), and for good reason. Prompt injection is not a traditional software bug. It is a fundamental property of the language modeling paradigm: Since LLMs are instructed to follow natural-language prompts wherever they appear in their context window, an embedded instruction, if carefully placed anywhere in that stream of input, can take control of the model.
Red teams need to test all three attack surfaces:
- Direct prompt injection attacks (the standard jailbreak test case) occur when someone inputs data into where the model expects it (a prompt) that overrides the system’s initial instructions or otherwise bypasses the model’s safety mechanisms. This vector is easiest to test since it’s so obvious.
- Indirect prompt injection is less obvious (but much more dangerous). It occurs when the LLM extracts content from another source (webpage, file, RAG doc, email, tool metadata) that includes hidden instructions. Since these instructions are embedded in its context, the model will follow them along with its original instructions.
- Multimodal prompt injection attacks include the previous two vectors but with image, audio, and document inputs. These sources can contain embedded malicious instructions that a human won’t understand but the LLM will read and execute. (Keep an eye on this attack surface growing as multimodal AI systems become more prevalent.)
Separate tooling is required to test each of these three surfaces, and they each have unique criteria for determining successful vulnerability discovery. The attack surface only grows from there when you account for agentic AI systems that can manipulate the world around them. Essentially, any webpage, file, or database the system can access is a potential indirect injection point.
Scalability, Resource Intensiveness & the Shortage of Skilled Professionals
Manual red teaming allows you to identify more nuanced vulnerabilities, but it doesn’t scale very well and requires a lot of resources. Automated red teaming is easily scalable but may not catch some nuanced vulnerabilities that manual review would catch.
Manually testing systems is difficult to scale. Attacker simulation software can find many vulnerabilities, but subtle vulnerabilities may be missed by an automated red team.
This is why many teams need a hybrid approach.
Balancing scalability and resource intensiveness is made even more difficult by there not being enough skilled professionals around. Red teams require specialized knowledge to execute correctly.
AI technology, and the threats surrounding it, are evolving quickly. Red teams need people with security knowledge as well as knowledge of new attack patterns.
Just ~1.5% of respondents from a global company survey stated they believe they have sufficient personnel to keep up with AI safety and security at their rate of adoption (Microsoft Digital Defense Report 2025). Additionally, red teaming for AI needs to be happening constantly, so companies can’t rely on manpower to manually test everything. Automated AI red teaming is a must.
Teams can look to trusted solution partners like Mindgard to help. We can help you provide scalable, automated red teaming while also giving you access to experts who can help you stay covered without draining your resources.
Learn about some of the top minds in AI security & AI red teaming here.
Multimodal and Contextual Risks
AI models operate across different modalities, such as image, text, or audio. As a result, evaluating their behavior over these inputs is expected to grow more complicated.
Testing AI over multimodal inputs will require red teamers to combine domain expertise with specialized tooling to identify vulnerabilities arising from interactions between modalities.
Although multimodal security concerns can pose roadblocks, they aren’t necessarily dealbreakers. For example, there are many challenges associated with AI red teaming that can slow progress. However, with collaboration between academia, industry, and policy makers, we can build standardized approaches to evaluating AI as well as create scalable tooling and an ecosystem for AI red teaming.
Partner With Mindgard for AI Red Teaming
AI red teaming is a must for ensuring the safe, ethical, and compliant use of generative AI and other AI systems in your organization. While it’s possible to red team internally, it requires time and resources that growing businesses might not have. That’s why organizations lean on Mindgard for specialized testing.
Our experts at Mindgard understand how important red teaming is to securing your organization’s AI systems. Mindgard’s Offensive Security for AI is security designed to protect AI systems from emergent threats only identifiable in an instantiated model and not found by traditional application security testing tools.
Reach out to Mindgard today to see how our AI red teaming services can help you secure your AI systems.
Frequently Asked Questions
What is a red team in AI?
An AI red team is a team of security researchers, domain experts, and automated tools that aggressively attack (through prompt injection, jailbreaks, data poisoning, model extraction, output manipulation) an AI system to identify safety, security, and regulatory gaps before malicious actors find them. Advanced red teams use a mix of internal teams (Microsoft's AI Red Team), external specialists (CSET, Humane Intelligence), and crowd powered adversarial testing (DEF CON GRT, UK AISI × Gray Swan).
Why are large language models being red teamed?
LLMs are red-teamed because they inherit all the security risks of classical software - and introduce novel failure modes like prompt injection, hallucinated output, training-data leakage, jailbreaks, and agentic misuse. Prompt injections were listed on OWASP LLM Top 10 (2025) alongside sensitive-information disclosure, supply-chain vulnerabilities, improper output handling, harmful levels of agency, and system-prompt leakage. Attacks with maliciously crafted prompts have also been shown to evade traditional ML defenses better than other evasion techniques according to Microsoft’s research into 100 products in 2025. That’s why red teaming needs to happen against each model generation.
Is there an AI red teaming certification?
Though there aren't many certifications specifically for AI red teaming, there are some legitimate options. For instance, SANS' SEC598: AI and Security Automation for Red, Blue, and Purple Teams recently went through an overhaul in 2025 to include generative AI and agentic automation with hands-on LLM labs built into red/blue/purple team workflows. Upon completing this course, students are qualified to obtain the GIAC Offensive AI Analyst (GOAA) certification.
HTB Academy's AI Red Teamer Job Role Path teaches students how to understand and implement red teaming AI workflows. Developed in collaboration with Google and based off of Google's Secure AI Framework (SAIF), this hands-on job role path walks learners through how to weaponize prompt injection, model privacy attacks, adversarial AI, AI supply chain risks, and AI deployment risks. This path culminates with the HTB Certified Offensive AI Expert (COAE) certification, which tasks students with performing industry-level red team exercises against realistic AI infrastructure including adversarial ML, data poisoning, evasion attacks, and LLM output manipulations.
What does NIST require for AI red teaming?
NIST published AI 600-1 (July 2024), which defines recommended practices for securing AI. Think of it as the generative AI supplement to NIST’s AI Risk Management Framework.
The guide defines 12 risk areas:
- CBRN Information or Capabilities
- Confabulation
- Dangerous, Violent, or Hateful Content
- Data Privacy
- Environmental Impacts
- Harmful Bias or Homogenization
- Human-AI Configuration
- Information Integrity
- Information Security
- Intellectual Property
- Obscene, Degrading, and/or Abusive Content
- Value Chain and Component Integration
From there, they map out recommended practices to adhere to for each risk area. Notice how the mapping explicitly calls out both pre-deployment red teaming/testing as well as responsible disclosure of security incidents.
If you dig into how to satisfy just the RMF’s Measure function, NIST explicitly mentions internal testing/red teaming to validate your model against hallucinations, bias, and privacy leaks.
This is all not required by law, but if you’re in a regulated space or part of the federal supply chain, you can probably expect it as a baseline.
What is red teaming in intelligence?
When red teaming is applied to intelligence, independent teams are used to think critically about weak spots, assumptions, and potential threats. Military, cyber, and AI programs commonly use red teams to analyze possible vulnerabilities.

