DeepSeek’s reasoning-first architecture, exposed internal logic, and layered workflows expand the prompt injection attack surface, allowing attackers to manipulate reasoning, tools, memory, and guardrails rather than just user inputs. Mitigating these risks requires layered defenses, continuous monitoring, and adversarial testing that analyze reasoning, behavior, and system-level signals across the entire AI stack.

Founded in 2023 in China, DeepSeek made waves in the AI space with its unique open-source setup and transparency. It’s no wonder the platform serves 22.15 million users every day.
Still, DeepSeek is far from perfect. Like all large language models (LLMs), DeepSeek is prone to prompt injection attacks. By carefully shaping inputs, attackers can manipulate DeepSeek to bypass its guardrails and cause real damage.
In this guide, you’ll learn how prompt injection attacks work in DeepSeek and its most common exploits. You’ll also learn how to prevent prompt injections from compromising information shared with DeepSeek.

Many teams assume DeepSeek operates like other LLMs, but treating DeepSeek as they would any other LLM creates blind spots in risk assessment.
Reasoning drives much more of DeepSeek’s decision-making process than other models. It provides greater visibility into internal thought processes, allowing attackers to target how the model thinks rather than just what it sees.
Models with large context windows are vulnerable to new persistence techniques. Once injected, instructions can survive across steps and influence later decisions.
Open-source variants expand the attack surface. Attackers can probe these models to observe behaviors and design precise prompt injections.
The traditional LLM flow is relatively simple: a user sends input, and the model generates an answer. The process ends.
DeepSeek follows a layered path. User input passes through system instructions. The model runs internal reasoning and triggers tool calls. It writes or reads memory and then produces output.
This difference is significant, as prompt injection in DeepSeek shifts from input manipulation to reasoning manipulation. Attackers shape the logic that drives decision-making, tool usage, and memory.
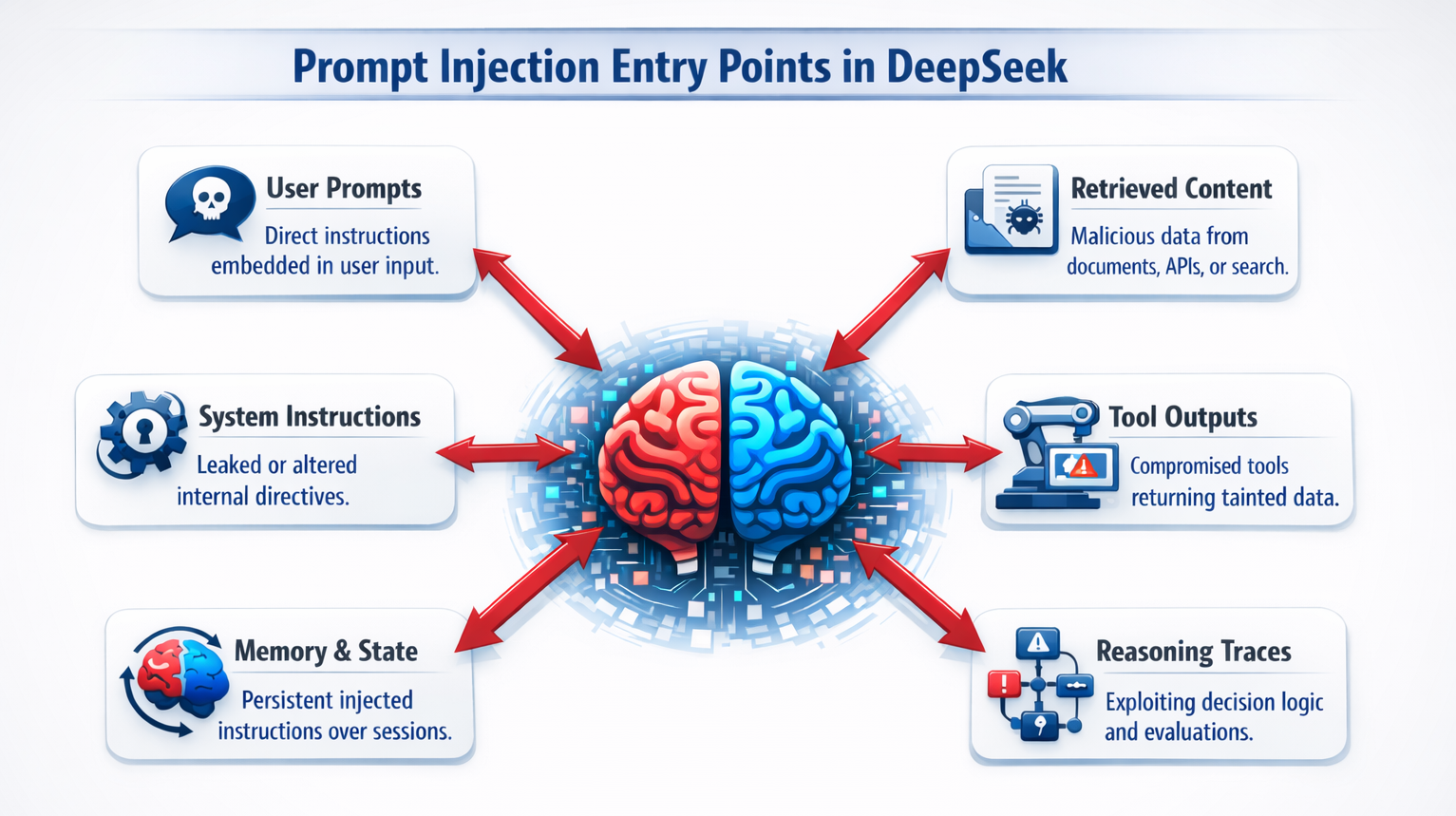
DeepSeek’s layered reasoning flow introduces more entry points for prompt injection. Common prompt injection entry points include:
While the following examples are not specific to DeepSeek, they illustrate how prompt injection can exploit modern LLM and agent architectures with similar multi-layer reasoning flows:
With multiple points of entry, DeepSeek expands the injection surface beyond the prompt itself, making prompt injection harder to prevent.

Prompt injections are particularly harmful because they’re difficult to spot. These are just some of the most common types of prompt injections that have successfully bypassed DeepSeek safeguards.
Some LLMs can be tricked into ignoring their rules with the right prompt injection techniques. With this exploit, an attacker manipulates the model to override system instructions with commands such as “Ignore previous instructions.”
DeepSeek models don’t consistently enforce an instruction hierarchy, and the LLM may treat the user’s malicious instructions as legitimate.
Jajilbreaking is a very common type of prompt injection. Instead of issuing a single instruction to break the rules, attackers gradually guide the model into unsafe territory by reframing requests as hypothetical or fictional.
Jailbreak attacks use role-playing, obfuscation, and context manipulation to get DeepSeek to generate outputs it would normally never create. For example, Mindgard’s technology identified encoding-based jailbreak risks in the Pixtral Large Instruct model, where attackers used obfuscation and layered instructions to bypass safety controls.
DeepSeek-R1 had a uniquely dangerous risk. A Trend Micro report found that DeepSeek-R1 included its reasoning in tags. A red team exploited this behavior to extract sensitive information embedded in the model.
Mindgard’s technology uncovered a comparable weakness in OpenAI’s Sora, where attackers were able to extract system-level prompts that shape model behavior.
In extreme cases, a prompt injection can actually reveal API keys, which hackers use to compromise other parts of your infrastructure.
Detecting prompt injection in DeepSeek requires visibility beyond user prompts. You need insight into reasoning, tool interactions, and system-level behavior.
Traditional prompt scanning misses most of the real attack surface because DeepSeek operates across multiple layers, where hidden instructions can influence outcomes.
Prompt injection in DeepSeek often appears first in the model’s reasoning rather than its output.
These signals matter because DeepSeek exposes rich reasoning pathways that attackers can manipulate. Detecting risk requires mapping how decisions evolve across model logic and connected systems.
Mindgard’s AI Security Risk Discovery & Assessment helps surface these hidden shifts by continuously analyzing model behavior, dependencies, and trust boundaries.
At the system level, prompt injection often reveals itself through abnormal tool and context behavior.
Continuous attack surface mapping and adversarial testing are essential for identifying these anomalies before they escalate.
Mindgard’s Offensive Security solution simulates real-world prompt injection paths, while artifact scanning inspects prompts, tool metadata, policies, and system artifacts for embedded malicious instructions that would otherwise go unnoticed.
Even when reasoning and behavior seem subtle, prompt injection can surface in model outputs.
Automated red teaming and runtime artifact scanning help validate whether guardrails and access controls hold up under adversarial conditions, rather than assuming they work by design.
Detecting prompt injection in DeepSeek requires continuous discovery of how models behave, what they connect to, and where attackers can intervene.
Effective detection combines reasoning analysis, behavioral monitoring, and artifact-level inspection across the entire AI stack, closing the gap between theoretical safety controls and real-world attack paths.

No single line of defense will prevent prompt injection attacks in DeepSeek. Instead, your organization needs a multi-layered approach to prevent prompt injection from every angle.
First, understand how your employees use DeepSeek. Internal users may unintentionally introduce risky prompts, while malicious actors test boundaries slowly over time. Monitoring how your team uses DeepSeek establishes a baseline for normal behavior, helping you spot unusual prompt patterns.
Prompt injections are designed to override your guardrails. Layered guardrails make it much harder for attackers to manipulate the model. Consider adding safety mechanisms such as:
Where you implement guardrails also matters. For example, DeepSeek reasons deeply, and it could reason itself into a dangerous state. Because of that, these guardrails should be in place both before reasoning and after the model generates a response.
Real-world research shows why layered defenses matter. Mindgard technology demonstrated that Azure AI Content Safety guardrails can be bypassed by carefully crafted adversarial prompts, revealing that static safety controls alone are insufficient to prevent sophisticated prompt-injection attacks.
Guardrails are essential, but they’re far from perfect. Developers also need to test their guardrails regularly. Red teaming and adversarial testing should be part of any DeepSeek deployment. This includes simulating:
Mindgard’s Offensive Security platform continuously stress-tests AI systems with automated red teaming, simulating real-world prompt injection and jailbreak scenarios at scale. Combined with exploit libraries and artifact-level analysis, this approach helps teams identify emerging attack patterns, validate guardrail effectiveness, and identify weaknesses before deployment.
No LLM is immune to prompt injection attacks, and attackers are only getting more creative. Understanding both common exploits and how to prevent them will help your team use DeepSeek while minimizing unnecessary exposure.
However, following best practices will only get you so far. Regular testing and simulated attacks are the best way to prepare for prompt injections before they happen.
Mindgard helps you deploy DeepSeek confidently without sacrificing speed or capability. It’s time to move beyond reactive fixes: Book a Mindgard demo now.
In some ways, yes. DeepSeek’s reasoning-first model has a distinct risk profile compared to other LLMs. For example, its exposed reasoning and long context handling can increase the damage of a prompt injection, especially if you don’t have proper guardrails in place.
Yes. Successful prompt injection can expose internal prompts, system rules, or reasoning traces. In high-risk scenarios, this may include credentials or API keys that attackers can use to cause even more damage.
The best way to understand your unique risk is to regularly test your LLM against the latest prompt injection exploits. Automated red teaming tools are particularly helpful for identifying vulnerabilities at scale. They also validate that your guardrails hold up under real-world conditions.


Mindgard helps organizations discover, assess and defend their AI systems. Spun out of more than a decade of AI security research at Lancaster University in the UK and headquartered in Boston and London, Mindgard operationalizes the expertise of AI researchers and offensive security practitioners through a Security Platform that performs Shadow AI discovery, AI red teaming, and run-time AI protection to assess and mitigate risk across models, agents, and applications.

The expert-level checklist for operationalizing NIST AI RMF, ISO/IEC 42001 and the EU AI Act. 190+ interactive items and a board-ready maturity scorecard. Built for CISOs, AI governance leads and ML engineering teams.
