
MCP servers turn prompt injection from a simple user-input risk into a distributed trust-boundary problem across tools, metadata, sessions, and external systems. Securing them requires layered controls, visibility across trust boundaries, and continuous adversarial testing to detect and contain indirect injection paths before they spread through agent workflows.

Model Context Protocol (MCP) servers standardize how large language models (LLMs) and AI tools interact with outside services. This technology makes it possible for an AI agent to manage your calendar, generate production-ready code directly from Figma designs, or connect a chatbot to a massive internal knowledge base.
While MCP servers dramatically reduce complexity and provide a better user experience, they also expand the prompt injection attack surface. Because MCP servers sit between models and real-world systems, your organization needs a multi-layered defense to prevent prompt injection attacks in MCP environments.
In this guide, we’ll explain why MCP prompt injection attacks are so damaging and provide best practices for securing every tool in your AI stack.
Anthropic created the Model Context Protocol in 2024 as a universal, open-source framework. Developers use MCP servers as a standard interface for reading files and executing functions. It is increasingly influential across the AI ecosystem, with tooling and integrations emerging across major model providers and platforms, including OpenAI and Google DeepMind.
MCP servers add many capabilities, especially to AI agents, making this technology more contextually aware and helpful. Unfortunately, MCP servers are a high-value target for prompt injection attacks.
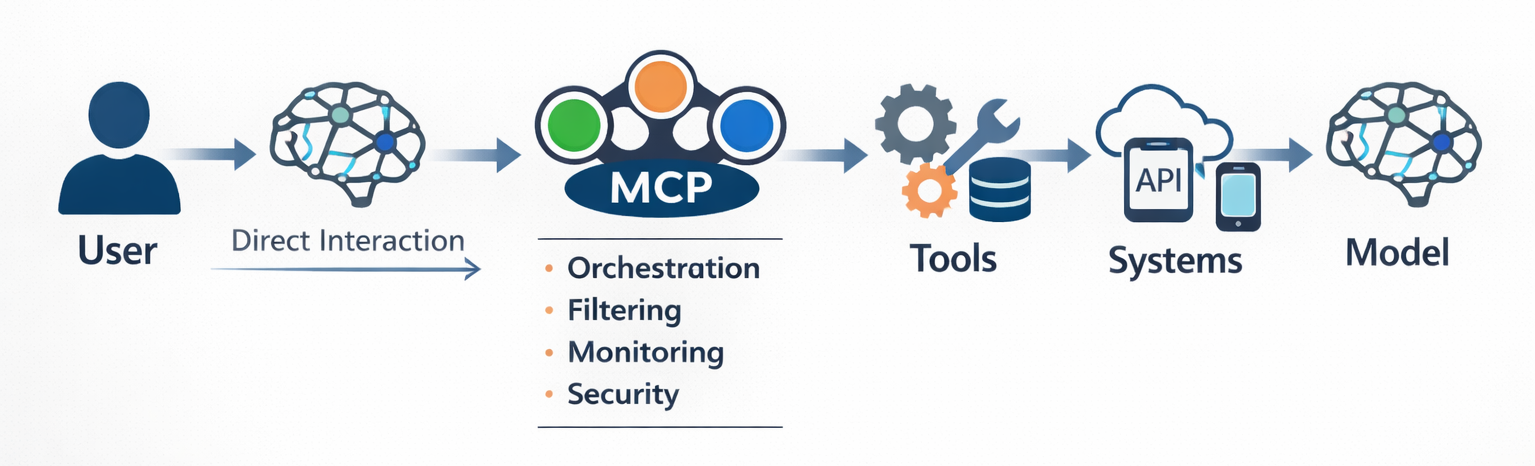
Prompt injection in MCP rarely originates inside the model. Instead, it emerges at trust boundaries upstream of inference.
MCP connects clients, servers, tools, and external systems. Each connection transfers context across a boundary, and each boundary introduces a new injection surface.
In traditional LLM applications, the flow is simple: a user sends input, and the model generates output.
MCP fundamentally changes this architecture. It inserts multiple intermediaries between the user and the model, transforming prompt injection from a user-input problem into a distributed systems problem.
In an MCP environment:
Without mapping these boundaries, it’s impossible to see where injection enters the pipeline.

Control in MCP is not centralized. Authority shifts at every stage of the pipeline, and each shift creates a new opportunity for prompt injection.
MCP is a distributed trust problem, not a single control surface. Treating it as a single system obscures the true attack surface. In practice, attackers target gaps between layers more often than they target the model itself.
Most MCP prompt injection attacks do not look like obvious prompts. They move through tools, metadata, and state.
Attackers target the places where context travels across systems. Below are the most common paths.
The most common type of indirect prompt injection against MCP servers happens via tool poisoning. Every MCP tool includes metadata (such as names, descriptions, and schemas) that large language models (LLMs) rely on to decide which tools to use and how to use them. If an attacker can tamper with this metadata, they can silently influence model behavior.
A poisoned tool description might instruct the model to:
Because these instructions live inside tool metadata, they’re invisible to end users and often overlooked during reviews.
Attackers exploit structured schemas that define how tools interpret inputs. They embed instructions inside fields that appear valid and well-formed. The model trusts the structure and executes the hidden intent.
A manipulated schema might cause the model to:
Attackers hide instructions in the context passed from one tool to another. That context is reused in unrelated tasks, carrying malicious intent across tool boundaries. The model treats inherited context as legitimate guidance.
Leaked context might cause the model to:
Attackers reuse session data across requests to trigger unintended actions. The model acts with privileges it was not meant to grant in the current context. Authority from one session is applied to another.
Replayed session data might cause the model to:
Attackers embed instructions in data retrieved from external systems. Tools ingest that content and pass it to the model as context. The model interprets retrieved data as operational guidance rather than untrusted input.
Injected downstream content might cause the model to:
Attackers inject malicious instructions into persistent agent memory. Those instructions survive across interactions and influence future decisions, and the model treats poisoned memory as a trusted state.
Poisoned memory might cause the model to:
Attackers chain tools so that one tool’s output becomes another’s input, allowing Injection to propagate across the tool pipeline, expanding scope and impact. The model executes compounded instructions without isolating trust boundaries.
A compromised tool chain might cause the model to:
The table below breaks down common MCP prompt injection attack paths, the primary entry point, attack mechanisms, typical impacts, and recommended controls.

The right type of attack can easily weaponize the same protocol that supercharges your agentic AI. Follow these best practices to secure MCP servers against prompt injections.
MCP servers should enforce per-client, per-user consent for all tools and data access. This approach prevents confused-deputy attacks, where an attacker tricks a trusted system into acting on behalf of an untrusted one.
Maintain a registry of approved values for each user-client combination. Before initiating any third-party authorization flow, the MCP server must check this registry and confirm that the request aligns with previously granted permissions.
Attackers can replay or forge unsigned or weakly protected cookies, giving attackers a foothold for session hijacking or cross-server injection attacks. That’s especially dangerous in MCP environments where sessions may span multiple tools or services. If you use cookies, they must be cryptographically signed.
MCP servers should treat all inbound requests as untrusted by default, even if they appear to originate from known clients. Every request should be fully verified and validated.
You should also avoid trusting sessions as an authentication mechanism. After all, a valid session doesn’t equal a valid request. This distinction is critical for preventing attackers from abusing intercepted session identifiers to inject malicious instructions into trusted workflows.
Even well-designed controls can fail in subtle ways. This is where continuous AI security testing matters.
Through red teaming, organizations can simulate adversarial techniques such as tool poisoning against MCP servers before real attackers do. Platforms like Mindgard Offensive Security are purpose-built for this kind of testing, helping teams identify unsafe tool metadata and injection paths that traditional security reviews often miss.
MCP servers transform prompt injection from a user-input problem into a distributed trust problem across tools, metadata, sessions, and external systems. Traditional controls like consent management, request validation, and context isolation are necessary, but they don’t reveal where hidden injection paths actually exist.
Mindgard’s AI Security Risk Discovery & Assessment provides that visibility by mapping real attack surfaces across models, tools, prompts, and agent workflows. Combined with Mindgard Offensive Security, which simulates real-world prompt injection techniques and tool poisoning attacks, teams can identify and stress-test MCP vulnerabilities before attackers do.
Together, discovery and adversarial testing shift MCP security from reactive fixes to systematic risk reduction. If you’re deploying MCP servers in production, understanding how your AI stack fails is the fastest way to reduce risk. Book a Mindgard demo to evaluate your MCP security posture before attackers do.
Traditional prompt injection targets user-facing inputs, like chatbot interactions, to manipulate a model. However, MCP-focused attacks happen indirectly.
MCP-focused attacks exploit tool metadata, session handling, or server-to-server communication. Instead of a user tricking the model, poisoned context from the MCP infrastructure misleads it.
Indirect attacks are hard to spot because malicious instructions aren’t part of any visible outputs, like user chats. They live in places most teams don’t regularly audit, such as tool descriptions, approved metadata, or server-side events. This makes them stealthy and persistent, especially if metadata can be modified after approval.
No. Authentication helps, but it doesn’t address attacks that exploit trusted components that behave in unsafe ways.
Prompt injection against MCP servers often abuses authorization logic, consent flows, or implicit trust in tool metadata. That’s why request verification and metadata controls are just as important as authentication.


Mindgard helps organizations discover, assess and defend their AI systems. Spun out of more than a decade of AI security research at Lancaster University in the UK and headquartered in Boston and London, Mindgard operationalizes the expertise of AI researchers and offensive security practitioners through a Security Platform that performs Shadow AI discovery, AI red teaming, and run-time AI protection to assess and mitigate risk across models, agents, and applications.

The expert-level checklist for operationalizing NIST AI RMF, ISO/IEC 42001 and the EU AI Act. 190+ interactive items and a board-ready maturity scorecard. Built for CISOs, AI governance leads and ML engineering teams.
