


In This Article
The top AI security risks of 2026 fall into three buckets. First, attacks on AI models themselves including prompt injection, data poisoning and model theft. Second, AI weaponized against your stack including deepfakes, AI generated phishing and automated vulnerability discovery. Third, governance failures that leave AI deployments uncontrolled.
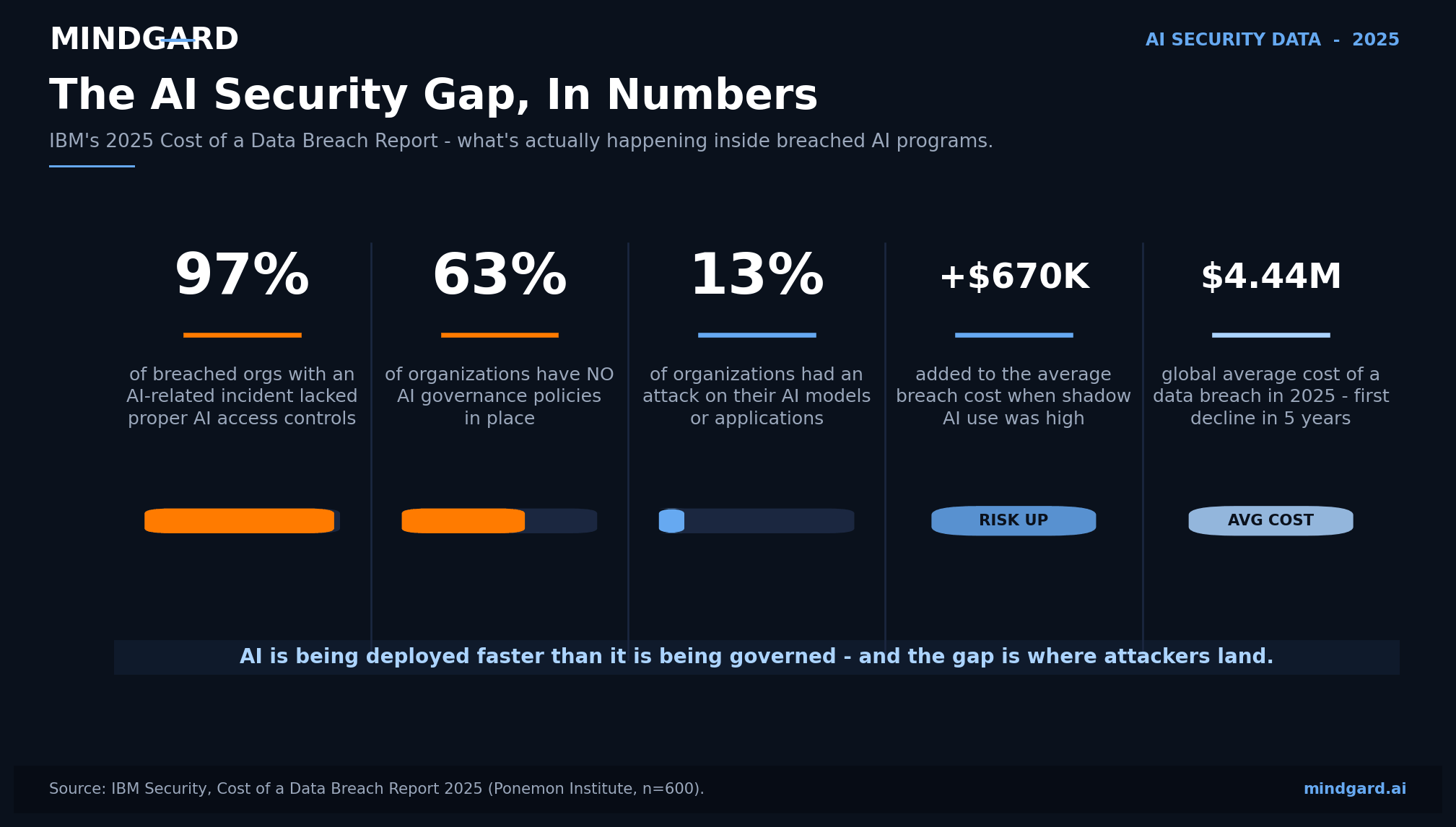
According to IBM's 2025 Cost of a Data Breach Report, 97% of breached organizations that suffered an AI related incident lacked proper AI access controls and 63% had no AI governance policies in place. The OWASP Top 10 for LLM Applications (2025), the NIST AI Risk Management Framework and MITRE ATLAS are now the three frameworks security teams use to map and mitigate these risks.
This guide walks through each of the top 10 risks, the controls that work and where AI red teaming fits in.
Aligning the Top 10 with the OWASP Top 10 for LLM Applications (2025)
The OWASP Top 10 for LLM Applications (2025) is the de facto industry framework for AI security risks. Published by the OWASP GenAI Security Project, it ranks the most critical vulnerabilities in LLM powered applications: LLM01 Prompt Injection, LLM02 Sensitive Information Disclosure, LLM03 Supply Chain, LLM04 Data and Model Poisoning, LLM05 Improper Output Handling, LLM06 Excessive Agency, LLM07 System Prompt Leakage, LLM08 Vector and Embedding Weaknesses, LLM09 Misinformation and LLM10 Unbounded Consumption. The latest update (2025) introduced risks from emerging agentic AI threats like tool misuse and goal hijacking.
Mindgard’s AI red teaming and assessment capabilities map to all ten categories. Below is an interactive table that outlines each risk, severity and corresponding Mindgard capability.
OWASP’s project chair makes it clear why the 2025 list is important today:
"Over the past two and a half years, the OWASP Top 10 for LLM Applications has shaped much of the industry's thinking on AI security. This year, we've seen agentic systems move from experiments to real deployments, and that shift brings a different class of threats into clear view."
- Steve Wilson, OWASP GenAI Security Project Board Co-Chair, Founder OWASP Top 10 for LLM, CPO Exabeam. OWASP GenAI Security Project, December 9, 2025.
5 Reasons AI Security Threats Are Becoming More Prevalent
The expanding scale and reach of AI systems, from generative models to ML-powered automation, has created new opportunities for attack. Multiple factors have converged that demand increased attention to AI security risks.
- Speed of adoption. Organizations are adopting AI technology and deploying it into production on mission-critical systems faster than they can keep it secure. IBM’s latest Cost of a Data Breach Report found 13% of surveyed organizations experienced an attack on AI models or applications.
- Emergent attack surfaces. AI presents new vulnerabilities that can be exploited in a variety of ways: model inversion, which can expose sensitive training data; data poisoning, which can alter model behavior; prompt injection, which can alter output; and more traditional adversarial attacks.
- Malicious use of AI. Bad actors can use generative AI tools to automate tasks that were previously difficult without coding expertise, like writing phishing emails or creating deepfakes. These attacks are scalable and can be launched with little technical expertise.
- Lack of governance. 63% of organizations have no AI-specific governance policies whatsoever (IBM). Without governance, organizations struggle to understand how AI is built, used, and monitored within their environments.
- Escalating costs. The average total cost of a data breach rose to $4.44 million in 2025 (IBM, Ponemon). High shadow AI usage increased organizations' breach costs by $670,000 per breach on average.
Solutions for the Top 10 AI Security Risks
Three in five cybersecurity leaders say their AI security posture is materially weaker than their traditional IT security posture (Darktrace, 2025 State of AI Cybersecurity report). Designing a perfectly secure AI solution is impossible. Organizations can take common sense approaches to mitigate the harms of AI security risks.
Here we explore the top 10 AI security risks facing businesses today--including several vulnerabilities commonly uncovered through AI penetration testing-- and what you can do to stop them.
1. Data Poisoning Attacks
Data poisoning occurs when an attacker inserts malicious data points into your training data set. The corrupt data then harms your model during training. Poisoned datasets can lead to inaccurate predictions, system-wide bias or dormant backdoors that activate after deployment.
You can prevent data poisoning by:
- Keeping AI data secure: Limit training data to only come from trusted, validated sources. Preferably you should build your models on curated datasets, not scraped or aggregated content. Building a pipeline of clean, transparent data is one of the best long-term defenses.
- Auditing your data: Use automated tools to scan your training data for abnormalities or adversarial manipulations. Data versioning can also track how your training sets change over time. These data records can be used to produce auditable evidence of potential tampering.
- Employing differential privacy or federated learning: These practices can limit the impact that any one data point has over the model’s behavior.
2. Model Inversion
A model inversion attack aims to leverage a model’s outputs to recreate or reverse-engineer sensitive aspects of the training data, possibly exposing private user data. Model inversion attacks threaten individual privacy and could reveal health, financial, or biometric information if leveraged appropriately.
Attackers have reconstructed users’ facial images, health records, and financial transactions through model inversion attacks.
Protect your model from this threat by:
- Using differential privacy: Employ techniques like differential privacy to inject statistical noise into your training data. Noise makes it difficult for attackers to recreate any one record.
- Restricting access: Limit who can access your model. Rate limit and protect endpoints with authentication and RBAC for APIs.
- Monitoring: Attacks will often perform repeated queries to test answers. Set up around-the-clock monitoring to detect and prevent attacks.
3. Prompt Injection Attacks

Malicious actors intentionally insert instructions into prompts that cause GenAI to behave in harmful ways, divulge secure information, or violate safety rules.
Attackers may trick the model into providing secure information or creating malicious software by using deceptive input.
The reason prompt injection works (and why it’s an open problem) is that LLMs do not distinguish between instructions vs. data.
Bruce Schneier wrote in Communications of the ACM:
"It is hard to think of an LLM application that isn't vulnerable in some way."
- Bruce Schneier, Fellow and Lecturer at Harvard Kennedy School. LLMs' Data-Control Path Insecurity, Communications of the ACM, May 2024.
That is why prompt injection is the single most cited LLM risk in the OWASP framework and why every defense below provides only partial protection.
Use these best practices to mitigate prompt injection attacks:
- Zero Trust approach: Treat prompt injection attacks as you would command injection attacks in general software security: always validate inputs, never trust, and employ layered defenses.
- Context separation: Separate prompts by context when possible. User-facing instructions should be segregated from system-level instructions to prevent bleeding behaviors.
- Input validation: Malicious prompts can come through normal user input. Sanitize user input and limit permissions to prevent users from entering special commands or prompt escaping tokens.
- Filters: Employ rule-based filtering in addition to AI-powered content filters to block dangerous or policy-violating prompts.
4. Model Theft and IP Leakage
Model theft, also known as model extraction, attacks happen when an adversary crafts inputs and queries your proprietary AI model via its API with the goal of training a local model to replicate its functionality. In other words, the attacker successfully steals your model without ever seeing weights or training data. With access to the stolen model, an attacker can redeploy it for themselves, evade paid usage quotas, or conduct offline attacks to discover additional weaknesses.
Organizations typically protect against model extraction by blending technical controls such as watermarking model outputs, rate-limiting queries per IP/user, and detecting anomalous query patterns with legal contracts such as API terms of use, model licenses, and takedown requests. AI red teaming can help you test how easily your model can be stolen given an adversary who can make sustained queries to your model.
Treat your AI model like you would source code or customer data. It deserves enterprise-grade IP protections. Technical controls are powerful when layered with legal safeguards (e.g., usage terms, model licenses) to minimize risk exposure. In addition to the previously mentioned strategies, you can prevent model theft by:
- Watermarking model outputs: Embedding hidden signals in model outputs that allow you to identify if your model has been copied.
- Detecting anomalous queries: Monitoring queries for behavioral patterns commonly associated with reverse engineering. For instance, if someone is systematically inputting the exact same/plain text into your model to probe for outputs, that is repetitive behavior that can be flagged.
- Rate limiting queries: Limit how many queries a user or IP can make to reduce extraction speed.
5. Evasion Attacks
Evasion attacks (aka adversarial examples) manipulate data as input to machine learning systems. Often undetectable to humans, these attacks can manipulate the outputs of machine learning models, particularly in image classification or computer vision contexts.
Security teams catalog these and related techniques using MITRE ATLAS, the open MITRE maintained adversarial threat matrix for AI systems modeled on MITRE ATT&CK, which gives red teams and defenders a common vocabulary for AI specific attack techniques.
Attacks can have physical real-world impacts in safety-critical environments such as self-driving cars or facial recognition software. One study demonstrated that by altering a stop sign with a few stickers, they could cause an AI model to recognize the sign as a speed limit sign.
MITRE recommends defending against this AI vulnerability through:
- Adversarial stress-testing: Stress-test models against adversarial examples to teach them how to recognize future attacks.
- Architectural defensiveness: Mitigate attacks by using robust model architectures and defenses.
- Anomaly detection: Use software to detect abnormalities in input data.
6. Lack of Model Transparency
AI systems are often referred to as black boxes since the developer or end user may have no idea how the model is deriving its outputs. This can make it hard or impossible to know when there are biases, errors, or manipulations being used in a model.
You can’t effectively audit a system for responsibility if you can’t see how its logic works. This is especially important in high-risk industries where model failure can cause serious real world harm like healthcare, finance, and criminal justice. Model explainability also allows for easier model behavior audits. If a model suddenly begins to exhibit strange or harmful behaviors, you will have a difficult time catching it if you can’t understand how decisions are made.
Obviously not every company can be transparent about their model’s inner workings due to IP restrictions. However, you should still be able to achieve both IP security and responsible use. Mitigate against a lack of transparency by:
- Implementing explainable AI (XAI) tools. These help identify how and why specific predictions were made by breaking them down into pieces we can understand.
- Using explainability frameworks.
- Using hybrid AI models. Sacrifice some raw performance for more interpretable models.
A lack of transparency might not intuitively seem like a security issue. But if you can’t examine your model’s decision-making process then you can’t easily detect malicious activity. Consider explainability a core functionality and an ethical safeguard.
7. Supply Chain Vulnerabilities
Building a completely custom AI solution from the ground up is challenging. To accelerate time to value, most businesses source components from third-party providers.
AI initiatives frequently incorporate external models, code libraries, data sets, or application interfaces that may have been compromised. Organizations can inadvertently import these shadow dependencies and fail to realize there are backdoors, malware, or vulnerabilities lurking deep within their AI stack.
Shadow dependencies lurking throughout the AI software stack can easily go unnoticed. What appears to be a normally functioning model from a public repository could actually have malicious capabilities activated by a hidden trigger.
Protect your organization from vulnerabilities in the supply chain by:
- Relying on validated models, libraries, and datasets from trusted sources.
- Tracking the source of all your data inputs and transformations.
- Automatically searching for deprecated or vulnerable elements.
- Regularly applying patches.
8. Insecure APIs and Integration Points

AI systems are frequently exposed to users through application program interfaces (APIs) that permit querying models, retrieving data, or integrating with other tools and platforms. Improving performance requires this information to be accessible to third-party tools and applications, but if left open, APIs can quickly become attackers’ favorite target.
APIs with poor security may permit bad actors to scrape your data, inject prompts, or steal entire models. This risk becomes even more significant when companies rapidly deploy AI tools into larger ecosystems without common security protocols, such as in multi-cloud or multi-tenant environments.
GenAI applications also run the risk of revealing too much information about prompt contexts through APIs. Additionally, verbose model outputs may accidentally expose information about internal logic. Developers will need to both harden their APIs and learn how to sanitize GenAI outputs.
System integration points are notorious for introducing security vulnerabilities that can be easy to miss but simple for attackers to exploit. Treat your APIs with caution, the same way you would your underlying infrastructure. Patch this hole in your AI protection by:
- Implementing API gateways: API gateways allow you to set limits on queries, as well as logging, IP blocking, and protocol-level security. APIs can also be secured behind authentication systems like OAuth 2.0, tokens, and mutual TLS.
- Restricting access: Limit who can access specific features of your API. Not every user requires access to every function; restrict privileges based on roles.
- Logging and alerting activity: Raise alerts when suspicious activity is detected, such as known malicious queries, traffic spikes, or repeated failed access attempts.
9. Impersonation and Deepfakes
Ever looked at a photo or video online and said to yourself, “There's no way this is real”? Well, chances are it isn’t. It's likely a deepfake.
Generative AI can now convincingly imitate voices, faces, and writing. This has led to deepfakes and all kinds of impersonation attacks that fool humans and machines. Attackers can spoof identities, forge documents, or manipulate media.
Deepfake technology threatens the very fabric of trust. Bad actors have used AI voice cloning to trick executives into wiring money to fraudulent accounts and AI-generated videos to deceive the public or damage reputations. However, there are steps you can take to defend against this AI security threat:
- Authenticating content: Spot fake content using digital watermarking, provenance metadata, and industry standards like C2PA.
- Using deepfake detection technology: Keep your detection technology and models up-to-date to catch synthetic or manipulated media.
- Training your team: Ensure your employees aren’t fooled by deepfakes. Train staff to recognize the dangers of AI-powered phishing emails, voice scams, and fake documents.
- Enabling multi-factor authentication: AI can be used to spoof your users” voices, videos, or writing. Instead of taking requests at face value, require layered identity verification. This is particularly important in high-risk verticals like healthcare and finance.
10. Poor Governance and Lack of AI Policy
Do you have AI systems deployed without any governance? Governance includes policy and rules around how your models are trained, used, and monitored, as well as who is responsible for what. Without some sort of AI governance in place, it’s all too easy for well-intentioned employees to break regulations, introduce risks, or abuse your AI systems.
The Darktrace 2025 State of AI in Cybersecurity report found that while confidence is increasing around defending AI attacks, only 42% of cybersecurity professionals report understanding their AI systems completely. A lack of governance and policy is a big reason why.
To improve your AI security posture, start by creating an AI governance policy. Your policy should lay out who is allowed to build, use, and maintain AI models, where they can be used, and what data can be used with them. Use AI model cards and SBOMs for AI to increase visibility into and accountability for your AI systems.
Lastly, make sure your teams are trained on using AI responsibly. This not only decreases your chance of risk happening but can help encourage a culture of responsible data use. As your AI usage grows, have your teams create documentation around what AI models are in use, who is responsible for them, and how they’re maintained.
Looking to build AI security knowledge in-house? Check out these AI security training courses and resources to get your team up to speed.
The NIST AI Risk Management Framework (a starting point for AI governance)
Released by the U. S. National Institute of Standards and Technology in January 2023, the NIST AI Risk Management Framework (AI RMF 1.0) provides voluntary guidance to organizations to manage risk throughout the AI lifecycle. The AI RMF outlines four functions around which organizations can apply its guidance: Govern (Policy & Accountability), Map (Context & Risk Identification), Measure (Analysis & Tracking), and Manage (Risk Prioritization & Response).
Subsequent releases include the Generative AI Profile (NIST AI 600-1) and a series of companion playbooks. The framework has seen wide adoption in U.S. federal procurement guidelines and is increasingly being referenced for EU AI Act compliance.
Bonus: Agentic AI - The Emerging Eleventh Risk
Outside of the big 10, there’s one category rapidly emerging that every security team should put on their 2026 map: agentic AI.
Agentic AI systems are AI agents that can plan, take actions and call external tools without per step human approval. Agentic AI introduces an entirely new category of risks, outside the scope of traditional LLM uses. The OWASP Top 10 for Agentic Applications (December 2025) ranks Agent Behavior Hijacking, Tool Misuse and Exploitation and Identity and Privilege Abuse as the top three.
The threat model changes because the blast radius of a successful prompt injection is no longer "the model said something wrong." It becomes "the agent moved money or sent the email or changed the database or deleted the file."
You can defend against agentic AI security risks by:
- Least privilege tool scoping. Limit each agent to only use the tools it needs to complete the task.
- Confirmation prompts for irreversible actions. If an agent can do something that can’t be undone (e.g., send money, delete data, make a public post) require explicit human approval.
- Agent focused red teaming. Test specifically for goal hijacking and tool misuse before deployment.
The table below breaks down the top AI security risks and key strategies to protect your systems.
Smarter AI Demands Smarter Security
From data poisoning and model theft to deepfakes and governance gaps, the top 10 AI security risks of 2026 are broad and fast moving, and the rise of agentic AI extends the threat surface further into autonomous decision-making. Each of these eleven blind spots is one that organizations can no longer ignore.
Artificial intelligence brings new threats, yes. But it also provides the very tools and methods you need to defend against them. Applied responsibly, with proper governance, transparency, and defense measures in place, you can fully leverage AI’s capabilities safely.
There is a price to pay if you get this wrong. The global average total cost of a data breach was $4.44 million in 2025 (IBM Cost of a Data Breach Report 2025). That’s the first year-over-year decrease in five years. However, organizations with extensive, undocumented AI (shadow AI) use saw costs rise by an additional $670,000 per breach. The most affordable way to lower those costs? Many organizations skip this step: continuous AI red teaming, with a documented and governed AI asset inventory.
Cybersecurity teams simply don’t have the time or resources to combat evolving AI risks on their own. Mindgard’s Offensive Security solution fills that gap. We empower organizations to combat evolving AI risks with continuous AI red teaming, AI discovery, and runtime protection aligned to the OWASP LLM Top 10 and NIST AI Risk Management Framework. We’ll help you stress test your models and hunt down vulnerabilities.
To better understand the breadth of potential vulnerabilities, security leaders can explore resources like the MIT AI Risk Repository, a database of more than 1,700 catalogued AI risks and real world attack scenarios for AI systems. You can also download the OWASP Top 10 for LLM Applications (2025) for the de facto industry framework on AI risk.
Book a Mindgard demo today to secure your AI systems against sophisticated attacks.
Frequently Asked Questions
What is the biggest AI security threat facing us today?
Data poisoning and prompt injection attacks are the most significant AI/LLM security threats we face right now. Both can be used to surreptitiously alter a model’s behavior, causing it to produce wrong or unsafe outputs, leak privacy-sensitive data, or be used in unintended malicious ways. With the increased availability of generative AI we’re also seeing deepfake impersonation and stealing of models emerge as pressing threats.
How can organizations start securing their AI systems?
Securing AI systems begins with mapping all AI assets (models, datasets, APIs, etc.) throughout your organization and applying basic security best practices such as access controls, input validation, and API monitoring. Next, develop a comprehensive AI governance policy to address AI use cases across your organization.
Can AI be used to protect against AI-related threats?
Yes. Security solutions can leverage AI to identify anomalous activity, surface adversarial attacks, and automate threat responses quicker than ever before. Some products, such as AI red teaming from offensive security providers like Mindgard can even mimic attacks against your own models to expose weaknesses before attackers do.
What risks to security do AI agents pose?
AI agents present three new top 10 risks according to OWASP Top 10 for Agentic Applications (December 2025): Agent Behavior Hijacking (the attacker convinces the agent to pursue the wrong goal), Tool Misuse and Exploitation (the agent calls its built-in tools in unexpected or harmful ways) and Identity and Privilege Abuse (the agent has access permissions greater than needed for the use case).
The mitigation pattern is the same in every case: least privilege scoping, human confirmation on irreversible actions and continuous agent focused red teaming.

