
Prompt injection and jailbreak attacks exploit different weaknesses in LLMs: prompt injection hijacks model behavior and downstream actions, while jailbreaks bypass safety guardrails to produce restricted outputs. Because these attacks often propagate through tools, pipelines, and workflows, effective LLM security requires layered defenses across model, application, and system layers.

Large language models (LLMs) streamline work and can improve accuracy, but they’re far from perfect. In fact, LLMs are frequently the targets of increasingly sophisticated cyberattacks. Prompt injection and jailbreaking are two of the most common adversarial attacks. While both exploit how your models interpret instructions, they target different points of failure.
Learn how prompt injections and jailbreaks differ from each other, and how to protect your LLM through proactive testing.

In a prompt injection attack, a malicious user feeds the LLM malicious inputs to manipulate its behavior. Instead of attacking the model’s code or infrastructure directly, the attacker exploits how the model interprets and prioritizes instructions. Prompt injections are difficult to spot because they mimic user-controlled inputs, which the LLM mistakes for real directions. These instructions often originate from non-user-controlled sources such as retrieved documents, tool responses, or external data.
The biggest risk of a prompt injection is losing control of your LLM. That can lead to data exfiltration, unauthorized access or actions, and reputational damage. Since prompt injection techniques don’t require breaking your model, it’s a powerful attack that requires specialized testing.

A jailbreak attack targets the LLM’s safety constraints and guardrails by manipulating how the model interprets its policies. Rather than injecting external instructions or data, it attempts to circumvent or bypass built-in restrictions through adversarial prompting.
Jailbreaks typically work through prompt engineering tactics that reshape the model’s reasoning, making restricted behavior feel permissible. For example, some users will role-play, asking the model to pretend to be in a fictional scenario where the rules don’t apply.
Other techniques include exploiting ambiguity, using metaphors or translations, and incrementally pushing the model’s boundaries.
Real-world testing shows how easily these techniques can succeed. Mindgard’s technology has identified jailbreak and encoding vulnerabilities in modern multimodal models, allowing obfuscated inputs to bypass safety controls and trigger restricted behavior. This shows how jailbreaks often rely on subtle manipulation of how models interpret language, rather than obvious rule-breaking.

Jailbreaks and prompt injection attacks are closely related and often overlap, but they differ in their primary objectives and impact.
Prompt injection manipulates inputs to hijack an LLM’s behavior, often by overriding instructions, accessing unintended capabilities, or influencing downstream actions. Jailbreaks try to convince an LLM to violate its safety guardrails and generate disallowed content.
Put simply, a prompt injection focuses on control, while jailbreaks focus on evading policies.
Real-world incidents show how these failures play out in practice. For example, researchers have demonstrated how system prompts can be exposed and, in some architectures, influenced or partially overridden, revealing hidden instructions and trust boundary weaknesses in LLMs. Mindgard’s extraction of OpenAI’s Sora system prompts demonstrates how attackers can bypass safeguards and gain insight into how models are controlled.
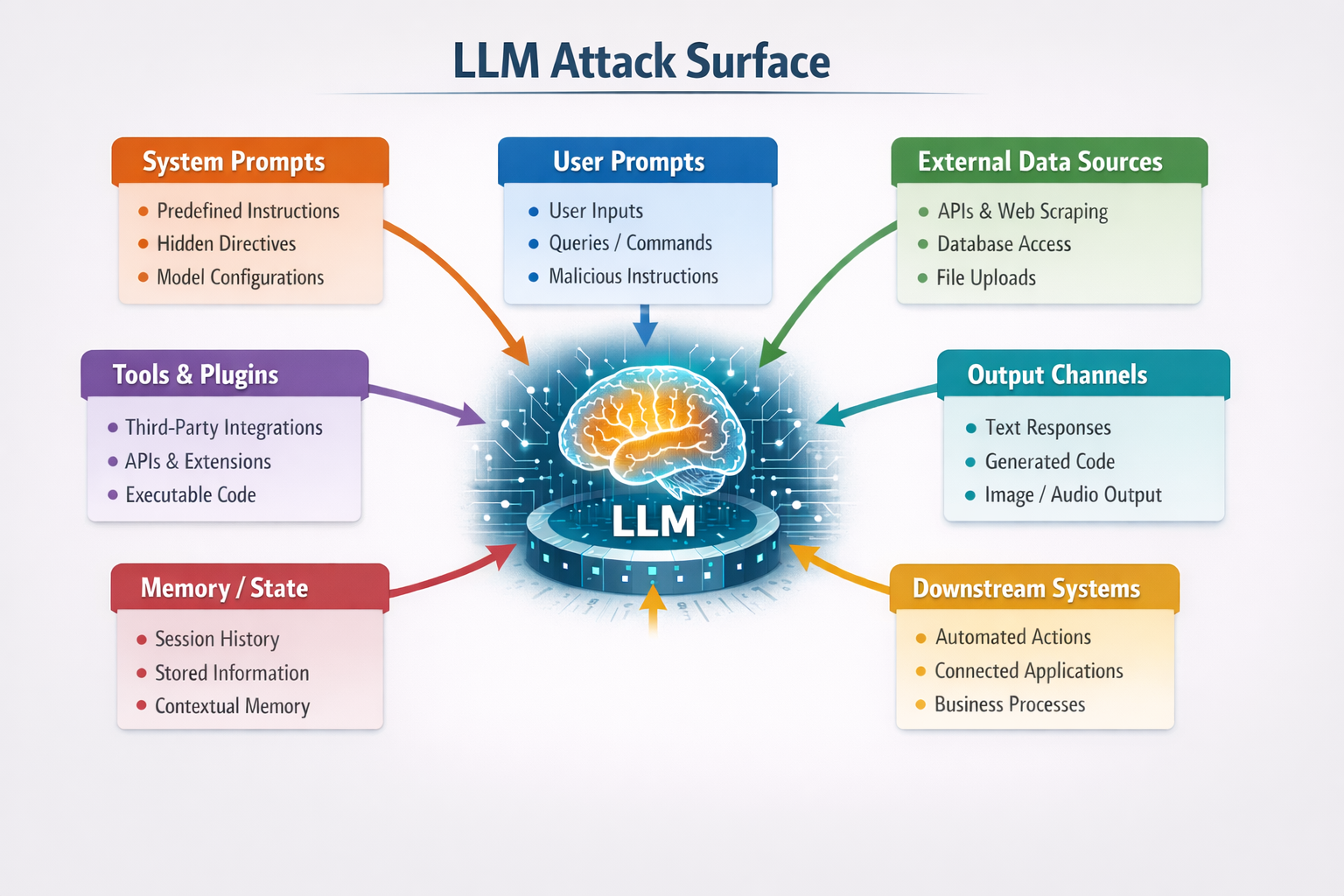
Most people think of prompt injection and jailbreaks as chatbot tricks, but that view overlooks the real risk. Attack vectors reside within your production systems.
Malicious prompts are embedded into documents. The model retrieves those documents and trusts their context, creating a common pathway for indirect prompt injection. Suddenly, your knowledge base has become an attack vector.
Injected prompts can alter agent behavior relating to tool use. This can cause the model to call incorrect APIs or leak private information. The attack surface transitions from manipulating text to manipulating actions.
Real-world vulnerabilities in AI agents show how dangerous this can be. In the case of coding agents, Mindgard’s technology identified how injected instructions could alter tool behavior, trigger unintended actions, and expose sensitive data.
Plugins allow you to extend copilot functionality by passing input directly to an external model. A malicious plugin response can manipulate behavior based on that single poisoned response.
Many LLMs operate within a technical pipeline that eventually calls a real API or executes business logic. If that logic is changed via prompt injection, it can propagate to downstream systems.
This kind of risk is already appearing in real development environments. Mindgard’s technology has identified vulnerabilities in AI-enabled developer tools that could allow injected instructions to influence application behavior and workflow logic.
When browsing the web, the content you view technically becomes part of the input. Malicious prompts can be hidden within web pages, scripts, and even metadata. The LLM ingests them as it would normal instructions.
The risk becomes more serious when LLMs interact directly with browsers and external content. Mindgard’s technology has shown how browser-integrated LLMs can be manipulated through injected prompts to take unintended actions, including gaining remote control over browser behavior.
Agents in a multi-agent system can send messages and pass work to other agents. If one agent is compromised, it can poison the others.
The moment your LLM starts integrating with databases, tools, and business workflows, you open up a new world of potential exploits. Engineers and security teams need to shift their focus to trust boundaries, data flow, and layers of control. This shift changes how defenses should be designed.
Some vulnerabilities can go even further than manipulating model outputs. Mindgard’s technology has uncovered cases where LLM-driven systems could be pushed toward persistent code execution or long-lived system state manipulation. These findings show how prompt injection and related attacks can evolve from language manipulation into long-term control over software environments.

Fortunately, since jailbreaks are a type of prompt injection, LLM security teams can mitigate these risks with many of the same defensive strategies. That said, they can’t be mitigated with a single control.
While every LLM requires a unique security approach, a layered approach across the model, application, and system layers can reduce the risk of prompt injection.
The model itself is the first layer of defense. You design the model to respond a certain way to malicious instructions. Example controls at this layer include:
Models are probabilistic. Eventually, they will give you the wrong output.
How your app talks to the model defines your boundaries of trust. Effective controls at the application layer help contain threats. Key controls at the application layer include:
Most real-world defenses reside in the application layer. This layer controls the blast radius.
It’s best to assume your model will be attacked eventually. The system layer improves long-term visibility and risk. Common system-level controls include:
LLM security is operational and requires ongoing oversight rather than a one-time configuration. Whether your primary concern is prompt injections or jailbreaks, LLM red teaming can help address both threats.
Red teams systematically probe models with adversarial prompts to uncover failures before real attackers do. Red teaming helps you identify:
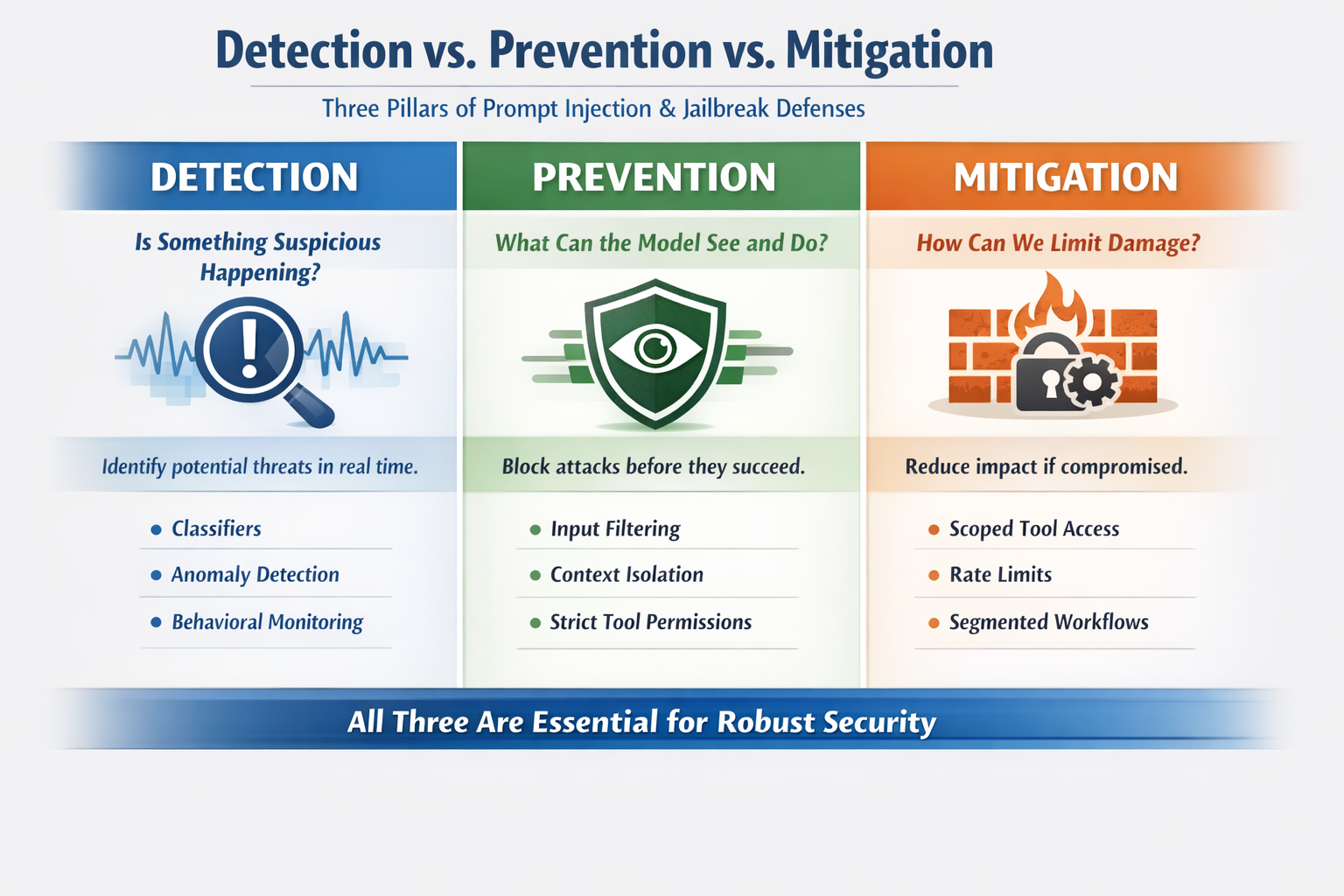
Prompt injection and jailbreak defenses fall into three categories: detection, prevention, and mitigation. Each plays a different role.
Detection focuses on identifying potential prompt injection or jailbreak attempts in real time. Detection mechanisms surface signals that something is wrong before damage occurs. Examples include:
Prevention mechanisms attempt to stop attacks from succeeding at all. They control what the model is allowed to see and do.
Ideal jailbreaking and prompt injection prevention mechanisms will block attackers from realizing their goals or knowing they’ve been stopped. Examples include:
Mitigation mechanisms aim to reduce the damage caused by an attack that bypasses other defenses. They limit what the model can do if it is compromised.
Attackers will realize their goal but might not know their actions are limited. Examples include:
Detection, prevention, and mitigation techniques each solve different problems. To have robust security, you need all three.
Prompt injections and jailbreaks are becoming incredibly common. Unfortunately, they exploit the very foundation of how LLMs work, which is why they can be so tricky to spot and stop.
The most effective defense isn’t chasing individual exploits, but understanding where models break, how systems expose risk, and what attackers can realistically do. That starts with visibility.
Mindgard’s AI Security Risk Discovery & Assessment maps how LLMs behave across real workflows. It reveals hidden attack paths, trust boundary failures, and high-risk interactions before they reach production.
From there, teams can move beyond guesswork. They can test assumptions, validate controls, and prioritize real risks.
Mindgard’s Offensive Security solution helps teams proactively identify, test, and mitigate prompt injection and jailbreak risks through continuous AI red teaming. Request a Mindgard demo now to pressure-test your model before attackers do.
No. Any LLM-powered system that processes user input or external content is vulnerable to prompt injections and jailbreaks. That includes any model that offers search assistance, summarization, agents, copilots, RAG pipelines, or tool-calling workflows.
First, it’s impossible to prevent all jailbreaks, especially since attackers often use advanced AI models to carry them out.
Guardrails can’t prevent attacks because jailbreaks rely on semantic manipulation rather than explicit rule-breaking. Attackers exploit ambiguity, hypothetical framing, or multi-step reasoning to make unsafe outputs appear allowed within the model’s own logic.
It’s both. Models are inherently susceptible because they follow language instructions.
However, application design also plays a big role in how exploitable a system is. That’s why LLM teams should invest heavily in proper prompt structure, context isolation, tool permissions, and monitoring.
Not necessarily. Both are susceptible to jailbreaking and prompt injection. Proprietary models like GPT-4 may allocate more resources to safety training, but they are also the primary targets of attackers, leading to well-documented jailbreaks.
Open-source models offer transparency for defenders to audit and harden, but they may initially have fewer built-in safeguards. The security of the overall application system is often more decisive than the model's origin.
Constantly. The field of adversarial AI is rapidly evolving. As soon as new model safeguards are released, researchers and attackers develop new methods to circumvent them.
This is why static, one-time security measures fail. Defense requires continuous monitoring, testing, and updating of your safeguards.


Mindgard helps organizations discover, assess and defend their AI systems. Spun out of more than a decade of AI security research at Lancaster University in the UK and headquartered in Boston and London, Mindgard operationalizes the expertise of AI researchers and offensive security practitioners through a Security Platform that performs Shadow AI discovery, AI red teaming, and run-time AI protection to assess and mitigate risk across models, agents, and applications.

The expert-level checklist for operationalizing NIST AI RMF, ISO/IEC 42001 and the EU AI Act. 190+ interactive items and a board-ready maturity scorecard. Built for CISOs, AI governance leads and ML engineering teams.
