
Prompt Injection in LLMs: How Attacks Work and How to Stop Them


Prompt injection is a system-level risk that lets attackers manipulate LLM behavior by exploiting how models interpret mixed instructions across prompts, content, and tools. Mitigation requires layered controls like least privilege, adversarial testing, and strict separation of untrusted content.
Key Takeaways
- Prompt injection is one of the most pervasive LLM risks because it exploits how models interpret instructions, enabling attackers to manipulate outputs and access sensitive data through both direct and indirect inputs.
- Preventing prompt injection requires layered defenses (not just guardrails), including least-privilege access, adversarial testing, and strict separation of untrusted content.

In This Article
Prompt injection is a system-level security risk. When successful, these attacks can cause LLMs to leak sensitive data, bypass authorization, execute unintended tool calls, or persist malicious behavior across sessions.
As LLMs are embedded into enterprise workflows, prompt injection becomes a control-plane failure, not a content issue.
Prompt injections have been around since at least 2022. Initially, these attacks against large language models (LLMs) focused on replacing trusted prompts with untrusted user input. While prompt injections have become more sophisticated, most generative AI have safeguards in place to prevent them.
Still, guardrails alone aren’t enough to prevent prompt injections. Attackers are creative, and even small changes to prompts or data sources can open new avenues for abuse. That makes prompt injection one of the most common and difficult risks to manage in LLMs.
In this guide, you’ll learn how prompt injection attacks work, the most common vulnerabilities attackers exploit, and the best practices organizations use to reduce risk.
How Do Prompt Injection Attacks in LLMs Work?

Prompt injection works because LLMs treat all text in context as potentially actionable. These models don’t execute code. They predict the next token based on the input.
System instructions, user prompts, retrieved content, and tool output all converge into a single text stream. To the model, there’s no built-in distinction between them.
That design introduces several structural weaknesses that attackers repeatedly exploit:
- Instructions are ambiguous. When multiple directives appear, the model infers which ones matter. Attackers exploit this by injecting prompts that appear relevant or helpful. The model blends instructions instead of rejecting them.
- LLMs can’t distinguish between code and data. A document, email, or API response may contain text that appears to be guidance. The model has no native way to treat it as non-executable. That is why indirect prompt injection works so reliably.
- LLMs process context linearly. Context is processed as a sequence, not as isolated scopes. Injected instructions only need to coexist with legitimate ones. In long conversations or RAG workflows, original intent becomes easier to override.
- Authoritative language is given added weight. Models respond to patterns in human language. Confident or official-sounding instructions often carry extra weight. Attackers mimic system messages or policies to steer behavior.
Prompt injection is a structural problem. LLMs treat language as both data and control, and that makes manipulation unavoidable without external safeguards.
Prompt Injection Entry Points in LLMs
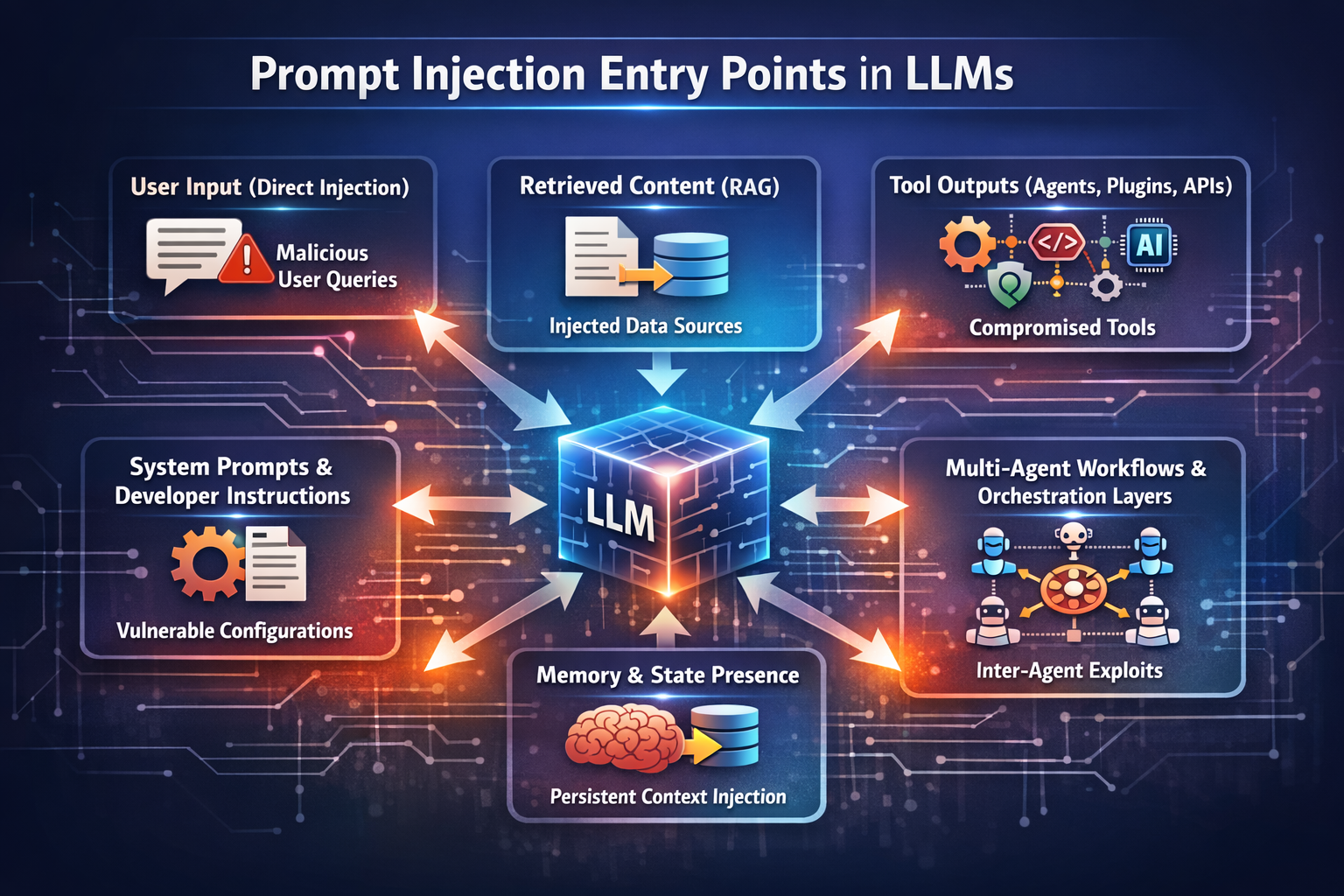
Prompt injection shows up anywhere an LLM accepts text and treats it as trustworthy. Modern systems expose many of these surfaces.
User Input (Direct Injection)
Attackers embed instructions directly into prompts, forms, messages, or uploads. The model treats the text as intent unless controls separate commands from content. This risk never disappears because user input is unavoidable.
Retrieved Content (RAG)
RAG widens the attack surface fast. Articles, PDFs, internal docs, and tickets can all carry hidden instructions. If retrieved content looks official, the model has no built-in way to ignore it without application-level enforcement.
Tool Outputs (Agents, Plugins, APIs)
Tool responses become part of the model’s context. When those outputs guide decisions or trigger actions, a single poisoned response can cascade through the workflow.
For example, Mindgard’s technology identified vulnerabilities in the Cline coding agent where inadequately scoped agent chains and tool outputs could influence downstream behavior and execution logic, even in workflows that appeared safe.
These findings highlight that tool outputs and orchestrated agents are active attack surfaces that can be manipulated via prompt injection techniques.
System Prompts and Developer Instructions
If system instructions leak, get reordered, or mix with untrusted content, core behavior can shift. Models follow the strongest instruction they see, not the one developers intended.
Memory and State Presence
Saved instructions turn a one-time injection into a persistent problem. The current prompt may appear clean, while its influence lingers across sessions.
Multi-Agent Workflows and Orchestration Layers
Shared context and chained agents multiply injection paths. One weak boundary can steer downstream agents that trust upstream output. At that point, the failure is systemic, not just a model issue.
This risk becomes even more pronounced in standardized orchestration environments. Mindgard’s guidance on securing Model Context Protocol (MCP) servers shows how prompt injection can propagate across tools, sessions, and agents when trust boundaries are not explicitly enforced.
In MCP-based systems, injected instructions don’t stay local. They can influence downstream tools and workflows unless requests, context, and permissions are tightly constrained.
Identifying these entry points conceptually is straightforward. Identifying which ones actually exist in a live LLM deployment is much harder. Mindgard’s AI Security Risk Discovery & Assessment maps real-world LLM workflows to uncover where prompt injection can enter through prompts, RAG, tools, memory, and orchestration layers, especially paths teams often miss during design reviews.
Defenses only work when they match the full attack surface. That’s why securing the model alone doesn’t solve the problem.
Common Types of Prompt Injection Attacks

What makes prompt injection especially dangerous is how sophisticated and varied these attacks have become. There are many types of prompt injection attacks that target LLMs, including:
Jailbreaking
In a jailbreaking exploit, the attacker persuades the model to break its own rules. Users typically frame requests as hypothetical situations to generate disallowed outputs.
Mindgard’s analysis of Pixtral Large Instruct showed how carefully encoded prompts could bypass safety constraints and influence model behavior, even when guardrails were in place. These findings illustrate how jailbreaking is achieved through prompt injection techniques that manipulate instruction interpretation and priority.
Prompt Leaking
Prompt leaks try to extract hidden system prompts or developer rules. By carefully phrasing questions or combining them with other injection techniques, attackers can trick the model into revealing sensitive information about your organization or the model itself.
Obfuscation
This prompt injection technique conceals malicious intent by writing instructions that replace letters with numbers, insert invisible characters, use synonyms, or split commands across lines. Attackers may also explicitly tell the model to “ignore” or “override” prior instructions in subtle ways that evade pattern-based filters.
Indirect Prompt Injection
Attackers hide malicious information in external content processed by LLMs rather than in direct user input. Webpages, documents, and emails are just some of the many avenues attackers can exploit for indirect prompt injection attacks.
Mindgard’s analysis of prompt injection attacks in DeepSeek and Copilot shows how content embedded in external workflows and deeply connected enterprise systems can steer model behavior toward unintended actions, even when those inputs are not part of the direct user prompt.
Indirect injection risk also extends beyond external content. Mindgard’s technology showed that model “leeching,” the leakage or cheap cloning of LLM skills and behavioral patterns, can expose indirect prompt injection vectors by enabling attackers to exploit leaked model logic or chained context influence.
How to Detect Prompt Injection in LLMs

Prompt injection typically manifests as changes in intent, behavior, or output. Prompt injection detection works best when you watch all three. Here are common signals to look for.
Reasoning-Level Signals
- Sudden shifts in model goals. A simple task turns into instruction-following or decision-making. The model starts complying with directions that never appeared in the system prompt.
- Hidden instruction compliance. The model follows directions that never appeared in the system prompt or user input. These often originate from retrieved documents or tool output that slipped into the control plane.
- Divergence from system objectives. Safety rules or constraints are acknowledged and then quietly ignored. The model’s priorities drift without an obvious trigger.
Behavioral Signals
- Unexpected tool usage. Tools are invoked without a clear need. APIs are called outside the task scope. Agent workflows include steps that do not line up with the original intent.
- Excessive or irrelevant context references. The model leans on documents, messages, or prior context that should not matter. Injected content starts driving decisions.
- Attempts to override system rules. Restrictions are reframed as optional or situational. The model treats guardrails as negotiable.
Output Signals
- Policy leakage. Internal prompts, rules, or safety logic appear in the response. These details should never surface.
- Hidden chain-of-thought exposure. The model reveals internal reasoning patterns or decision logic that weren’t requested.
- Unauthorized data disclosure. Sensitive or restricted information appears in the output. At this point, prompt injection has already succeeded.
Real-world research shows why guardrails alone are insufficient. Mindgard’s technology revealed that Azure AI Content Safety controls could be bypassed, allowing restricted outputs to be generated despite active moderation policies. This reinforces why prompt injection detection and layered defenses are critical.
3 Best Practices for Preventing Prompt Injection Attacks in LLMs

It’s impossible to design an attack-proof LLM. However, developers and security teams can reduce real-world risk by applying layered controls that align with how prompt injection actually enters the system.
1. Always Enforce Least Privilege
Primary attack surfaces addressed:
Tool outputs, agents, plugins, APIs, and automated workflows
LLMs should never have more authority than necessary. That means:
- Restricting access to tools, APIs, plugins, and sensitive data by default
- Scoping permissions to specific tasks rather than granting broad capabilities
- Preventing models from taking high-impact actions
Prompt injection becomes high-impact when the model can trigger real actions. Limiting what the model is allowed to do limits how far an injected instruction can propagate.
For example, a compromised model that can only summarize text is far less dangerous than one that can call internal APIs or modify data.
2. Conduct Continuous Adversarial Testing
Primary attack surfaces addressed:
User input, retrieved content (RAG), tool outputs, instruction conflicts
If you don’t actively try to break your own LLM, attackers will do it for you. Adversarial techniques, such as red teaming, help surface instruction conflicts, unexpected behavior, and indirect injection paths before deployment.
Because LLMs do not inherently know which text is safe to follow, testing must include:
- Direct prompt injection attempts
- Indirect injections hidden in retrieved or tool-generated content
- Multi-step workflows where injected instructions propagate across tools or agents
Adversarial testing should be continuous, especially after model updates or new integrations.
3. Segregate Untrusted External Content
Primary attack surfaces addressed:
Retrieved content (RAG), user uploads, emails, webpages, documents
Processing external content introduces indirect prompt injection risk. LLMs must not treat retrieved text as authoritative instructions.
Webpages, documents, emails, and user uploads should always be:
- Clearly separated from system and developer prompts
- Explicitly labeled as untrusted content
- Prevented from influencing tool selection or execution
Attackers exploit ambiguity in instruction priority. Without enforced boundaries, models attempt to reconcile conflicting directives rather than rejecting malicious ones outright.
Prepare For the New Generation of Cyber Attacks
Prompt injections are a risk for any LLM. As attacks become more sophisticated, developers need to design their models with security in mind from the ground up.
What makes prompt injection especially challenging is that it doesn’t rely on a single exploit. That means traditional perimeter defenses aren’t enough.
Mindgard’s Offensive Security solution, including Run-Time AI Artifact Scanning and Continuous & Automated AI Red Teaming, is the best way to ensure your LLM guardrails are effective in the real world. Find where your model is vulnerable: Book a Mindgard demo now.
Frequently Asked Questions
Are prompt injection attacks the same as jailbreaks?
Not exactly. Jailbreaking is a type of prompt injection. Prompt injection is a type of attack that includes any attempt to manipulate an LLM’s behavior through malicious inputs.
Jailbreaks focus on persuading a model to ignore its guardrails, typically through social engineering or hypothetical framing.
Can system prompts fully prevent prompt injection?
Unfortunately, no. Strong system prompts are important, but they can’t prevent prompt injections by themselves.
Effective prevention requires multiple layers, such as permission controls, adversarial testing, content segregation, and monitoring.
Are any LLMs resistant to prompt injections?
No. Any LLM or application using LLMs is at risk of prompt injection. Since these attacks focus on the very core of how LLMs work, it’s unlikely that these models will become immune to prompt injections any time soon.

