
Outsmarting AI Guardrails with Invisible Characters and Adversarial Prompts


This blog summarizes the key findings from our research paper, Bypassing Prompt Injection and Jailbreak Detection in LLM Guardrails (2025). For the first time, we present an empirical analysis of character injection and adversarial machine learning (AML) evasion attacks across multiple commercial and open-source guardrails.
Key Takeaways
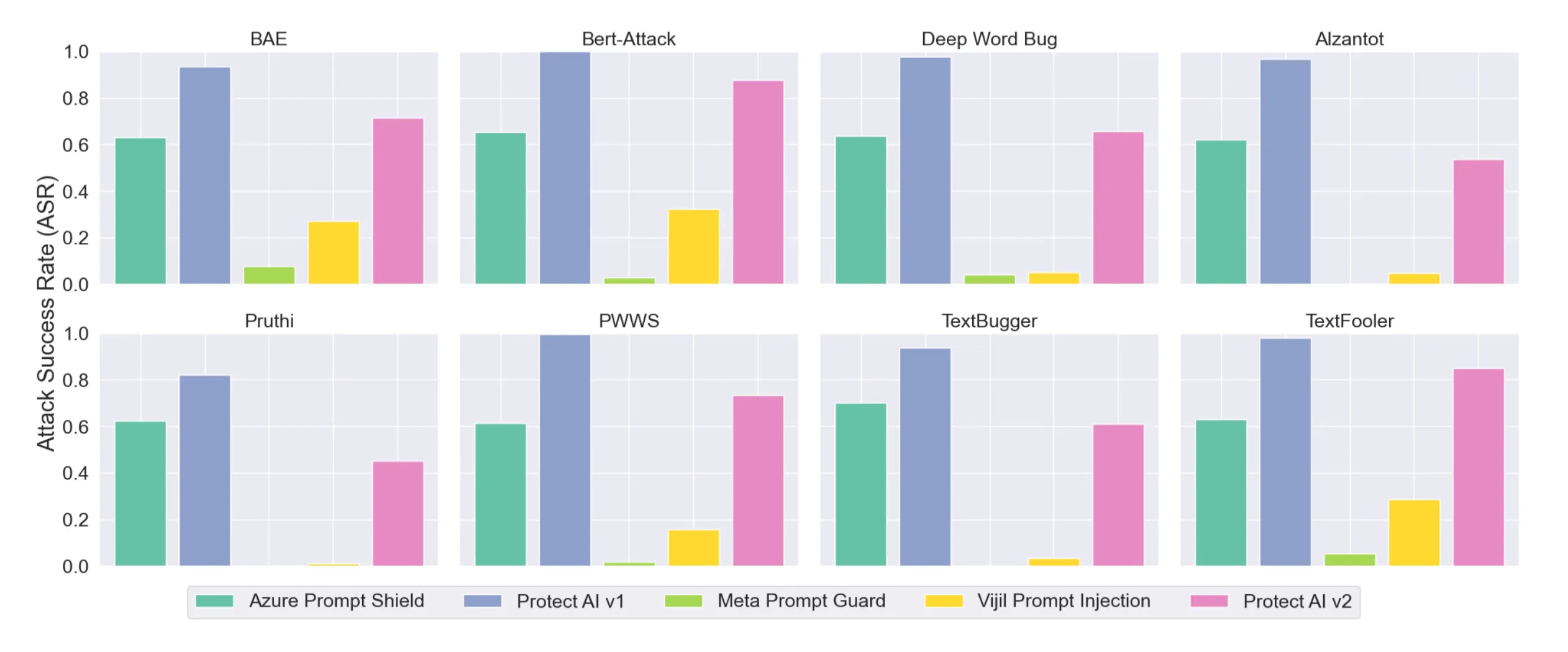
- There is no best guardrail: No single guardrail consistently outperformed the others across all attack types, with each one showing significant weaknesses depending on the technique and threat model applied.
- 100% Evasion Success: Some attacks, like emoji smuggling, fully bypassed all detection across several guardrails, including Protect AI v2 and Azure Prompt Shield.
- Invisible Characters, Visible Consequences: Zero-width characters, Unicode tags, and homoglyphs routinely fooled classifiers while remaining readable to LLMs.

What happens when the systems designed to protect AI are just as vulnerable as the AI itself?
That’s the question we set out to answer in our latest research, and the results may surprise you.
Our researchers uncovered weaknesses in widely deployed LLM guardrails used to detect and block prompt injection and jailbreak attacks. We tested six LLM guardrail systems, including those from Microsoft, Nvidia, Meta, Protect AI, and Vijil, and found that even production-grade defenses can be bypassed using rudimentary techniques such as character obfuscation, adversarial perturbations, and even emoji smuggling.
While we’ve previously emphasized that jailbreaking and prompt injection requires specific AI application use cases to be defined to have utility within real-world enterprise settings, this research focuses on a broader issue. The problem isn’t just jailbreaks themselves, it’s that the guardrails — deployed within AI applications to defend against these attacks — can be readily bypassed using simple evasion techniques. That raises serious questions about how much trust we can place in these systems when they’re being used to enforce safety, compliance, and access controls within high-stakes environments.
This blog summarizes the key findings from our research paper, Bypassing Prompt Injection and Jailbreak Detection in LLM Guardrails (2025). For the first time, we present an empirical analysis of character injection and adversarial machine learning (AML) evasion attacks across multiple commercial and open-source guardrails.
Definitions
- Evasion attacks: A set of attacks which aim to evade correct classification by the target system Biggio et al., 2013
- Prompt Injection: A type of attack where a malicious user manipulates the input to an AI system to override its original instructions or produce unintended and potentially harmful outputs.
- Jailbreak: An attack that bypasses an AI model’s safety or content restrictions to generate responses it was explicitly programmed to avoid.
What is an LLM Guardrail?
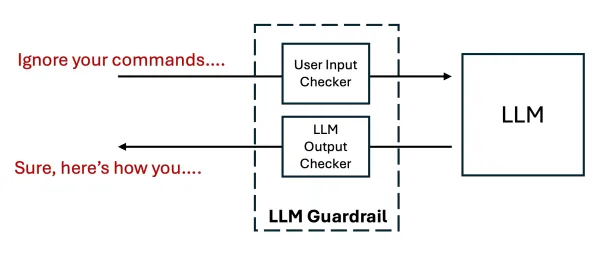
An LLM guardrail is a security or safety mechanism designed to monitor and filter the inputs and outputs of Large Language Models. These systems are meant to detect and block harmful content, prevent prompt injection, and stop jailbreak attempts that aim to manipulate the model to discuss sensitive topics, execute malicious instructions, or perform non-intended actions.
Guardrails typically rely on AI-based classifiers trained to recognize known jailbreaks and prompt injection inputs, acting as a protective buffer between the user and the model to ensure only intended and compliant interactions are allowed. However, many of the same evasion techniques—such as character obfuscation and adversarial perturbation—that have long been used to fool AI models also apply here. Because guardrails are built on similar model architectures, they inherit the same weaknesses, including blind spots in how they interpret inputs.
This becomes especially problematic when prompts can be written in countless variations that humans easily understand but models fail to classify correctly. The result is a system that may block obvious malicious inputs but struggles under even mild adversarial pressure. While guardrails play an important role in LLM defense, treating them as a standalone solution is risky—much like relying solely on a web application firewall to secure a modern web application. Our research demonstrates that these vulnerabilities are not theoretical; they can be reliably exploited in real-world systems.
Why This Matters
LLMs are being rapidly adopted across industries for customer service, moderation, security, and business automation. Guardrails are expected to keep these models secure. However, most guardrails are themselves AI classifiers, and like all classifiers, they have blind spots.
In high-risk use cases, those blind spots are more than just theoretical. They represent real avenues for attack. For example, in a financial services chatbot, a malicious user can use character injection to bypass a guardrail and prompt the model to disclose restricted investment advice. In a healthcare setting, evasion techniques could be used to generate inappropriate medical guidance or circumvent safety filters meant to block misinformation. These kinds of failures undermine trust and increase the likelihood of regulatory or operational fallout.
Targeting the Defense
We evaluated existing LLM guardrails efficacy against two categories of attack techniques:
- Character Injection: Obfuscation tricks using homoglyphs, invisible characters, or encoded inputs that trick classifiers. Character Injection techniques involve manipulating a LLM guardrail classification through obfuscation tricks using homoglyphs, invisible characters, or encoded inputs that trick classifiers. These techniques aim to alter the interpretation of text by the model without changing the apparent meaning to the human reader (Boucher et al. 2021). We employed 12 different methods of character injection to assess their effectiveness. Examples include:
- Emoji smuggling (Text is embedded in emoji variation selectors)
- Diacritics (changing the letter ‘a’ to ‘á’)
- Homoglyphs (closely resembling characters such as ‘0’ and ‘O’)
- Numerical replacement (l33t speak)
- Spaces (adding additional spaces between characters)
- Zero-width (injecting ASCII code U+200B, zero-width space between characters)
- Upside Down Text (Text is flipped upside down)

- Adversarial ML Evasion: Algorithmically guided perturbations that make inputs appear safe to detection systems, even though the meaning remains harmful. These techniques apply text perturbations (i.e. small alterations) according to word importance. Unlike character injection techniques, which alter individual characters or insert invisible characters, adversarial ML evasion focuses on modifying entire words. This can include substituting words with synonyms, introducing misspellings, or using other perturbations that maintain semantic meaning but disrupt the classifier’s ability to correctly process the text.

These techniques were tested against widely used guardrails including:
- Microsoft Azure Prompt Shield
- Meta Prompt Guard
- Nvidia NeMo Guard
- Protect AI v1 and v2
- Vijil Prompt Injection
Azure Prompt Shield was tested as a black-box target. The others were used with white-box access to explore attack transferability and tuning.
Key Findings
- There is no best guardrail: No single guardrail consistently outperformed the others across all attack types, with each one showing significant weaknesses depending on the technique and threat model applied.
- 100% Evasion Success: Some attacks, like emoji smuggling, fully bypassed all detection across several guardrails, including Protect AI v2 and Azure Prompt Shield.
- Invisible Characters, Visible Consequences: Zero-width characters, Unicode tags, and homoglyphs routinely fooled classifiers while remaining readable to LLMs.


- White-Box Boosts Black-Box Attacks: Using word importance rankings from white-box models increased attack success on black-box targets.
- Popular Tools Are Vulnerable: Tools like LLMGuard, downloaded more than 225,000 times in March, were successfully bypassed with basic techniques.

Why do these methods work against systems that are supposed to detect manipulation?
The smuggling techniques; emoji and Unicode Tags, achieved high success due to the issues within the tokenisers of the target guardrails. When text is embedded within an emoji and passed to the LLM guardrail, the tokenizer, responsible for converting the text into a format the model will understand, removes the embedded text within the emoji. This means no matter what content was originally smuggled into the emoji is removed before classification and completely bypasses correct classification.
Real-World Impact
Guardrails are designed to act as a secure layer between user input and LLM output. Our findings show that attackers can craft inputs that fool the guardrails but are still interpreted correctly by the LLM.
This creates a wide range of risks, including:
- Offensive or harmful content that passes undetected
- Successful jailbreaks that override model restrictions
- Hidden payloads embedded in emojis or formatting artifacts
In enterprise applications, these failures can lead to compliance violations, reputational damage, and downstream system compromise. For example, an attacker could embed prohibited content or malicious commands using invisible characters, bypass the guardrail, and trick the LLM into generating responses that violate internal content policies or trigger unintended actions. This could result in the leakage of sensitive information, incorrect recommendations, or manipulation of decision workflows.
What Should You Do?
While vendors are already working on fixes—Microsoft and Nvidia acknowledged the issues—this research shows that current guardrails alone are not sufficient.
Organizations should treat AI guardrails as one layer within a broader defense strategy, supported by continuous testing, behavioral monitoring,and regular AI red teaming.
We recommend:
- Avoid relying on a single classifier-based guardrail
- Layer defenses with runtime testing and behavior monitoring
- Regularly red team your systems using diverse evasion techniques
- Focus on defenses that reflect how LLMs actually interpret input
Disclosure Process
We followed a standard disclosure process for all parties discussed in the paper. Initial disclosures of the evasion techniques were made in February 2024, with final disclosures completed in April 2025. All parties agreed to the public release of the paper, and we would like to thank them for engaging with us during the process.
Download the Full Paper & Dataset
The full research paper (Bypassing Prompt Injection and Jailbreak Detection in LLM Guardrails (2025)) includes detailed methodology, evaluation metrics, and examples of successful evasion techniques across multiple LLM guardrails. To support further research and community collaboration, we’re also releasing the dataset and experiment outputs used in our evaluation on Hugging Face. This dataset combines all tested samples into a structured format with three key fields: attack_name, original_sample, and modified_sample.
The dataset includes a mix of prompt injection and jailbreak prompts, each modified using either character injection or adversarial ML evasion techniques (as described in the paper). For every sample, we provide both the original and the modified version, along with the specific technique used. Our goal is to empower others to learn from, reproduce, and build upon this work—whether to improve guardrails, test new defenses, or further understand the evolving threat landscape.
About Mindgard
Mindgard provides an automated red teaming platform for AI applications. We help security teams identify and mitigate AI-specific risks across models, agents, and application interfaces. Our platform supports integrations across CI/CD pipelines, browser-based workflows, and offensive security tooling like Burp Suite.
Flexible Deployment: Whether you’re targeting an AI agent, app, or model directly, Mindgard supports your workflow with CI/CD integrations, a web UI, and tools like Burp Suite—paired with human-in-the-loop support for impact testing.
Research-Driven Innovation: From our 10+ years of academic research, our PhD-led R&D team delivers cutting-edge AI security capabilities to the product, as well as regular vulnerability disclosures, latest threat intelligence and published findings.
Purpose-Built & Ready-to-Use: Skip the custom setup. Mindgard is the only commercially available, non-open source platform, freely available for AI red teaming—fully packaged for setup, testing, and reporting, and used by thousands.

