

Compilation as a Defense
Enhancing DL Model Attack Robustness via Tensor Optimization

With the advent of AI and its rapid integration into almost every facet of our lives, mechanisms to ensure its security and trustworthiness are now a necessity. As outlined within NIST’s AI Risk Management Framework and practiced by leading AI-mature enterprises, red teaming AI systems is an effective approach towards achieving AI security. Such red teaming enables the identification and mitigation of security threats to AI applications, enabling organizations to accelerate their AI adoption.
We are excited to announce that starting today, Mindgard supports automated red teaming of image AI models hosted anywhere! This new capability enables AI and security teams to conduct rigorous testing of image models to identify weaknesses, biases, and potential misuse scenarios, ultimately aiming to enhance their security, reliability, and ethical performance across a wide range of applications.
At Mindgard, we have been developing and implementing adversarial Machine Learning (ML) attacks that can exploit vulnerabilities within AI models to deceive, manipulate or extract sensitive information. In the case of image classification models, evasion attacks introduce subtle, often imperceptible alterations to input images that can lead the model to make incorrect classifications or predictions.
Such threats can undermine the reliability and security of AI applications, ranging from facial recognition to autonomous driving systems resulting in privacy breaches, misidentification, and even physical harm (more about these risks in our deepfake detection bypass blog). Image models have been around for a while and most common real-world applications of image models include autonomous vehicles, medical imaging, retail and e-commerce, social media and content moderation, agricultural and environmental monitoring, security and surveillance, and manufacturing quality control.
With the rise of the Multi-modal and Mixture-of-experts model, we can expect to see even more innovative use cases emerge across various industries and domains including safety critical environments. Therefore, enhancing AI model security against such adversarial attacks is crucial to improve their safety and reliability.
With this update, Mindgard’s platform and CLI have been updated to support image models. This means that any image classifier mode can now be tested - all you need is access to the model inference (or API) and a diverse dataset of challenging images. Mindgard includes specific testing scenarios (or attacks, as we like to call them) in our threat library to probe for evasion biases and vulnerabilities, and you can use our simple specification to start. Once the red team tests have completed, security risk scores of your AI model are presented within the terminal, and a URL is generated that navigates to detailed results within your Internet browser.
A step by step tutorial demonstrating the new functionality is available in our CLI repository here, and the GIF below shows a red teaming test against an image model in action:
In the example above, we define our target model configuration using a .toml file. We’ve used the inference endpoint URL from our hosted HuggingFace model ViT-based MNIST ZIC, the testing dataset mnist, and configured the image labels to expect from our model. In the detailed model tests results page of the AI risk report shown above, you can see that Mindgard identified a critical and a high severity threat against ViT-based MNIST ZIC when exposed to SquareAttack (risk score of 80%), and BoundaryAttack (risk score of 100%), indicating high susceptibility to threats of evasion attacks.
Our free trial i.e. Mindgard AI Security Labs currently provides access to two black-box attacks (i.e. no knowledge of internal functions) for image models: SquareAttack and BoundaryAttack. SquareAttack is an adversarial technique that perturbs images using square-shaped patterns, aiming to produce misclassification while maintaining a minimal alteration to the image. Similarly, BoundaryAttack is a decision-based attack that starts with a noise filter perturbation that is iteratively reduced while still causing the same misclassification in the target model. These attacks are designed to test the robustness of image classifiers against adversarial inputs, ensuring that image models can handle potential manipulation without knowledge of the underlying model or access to the AI model’s code, weights or architecture. SquareAttack sends 300+ perturbations and BoundaryAttack sends 3000+ perturbations each to red team image classification models.
To get you started, we’ve included a variety of image datasets covering various domains to test your AI models against, including:
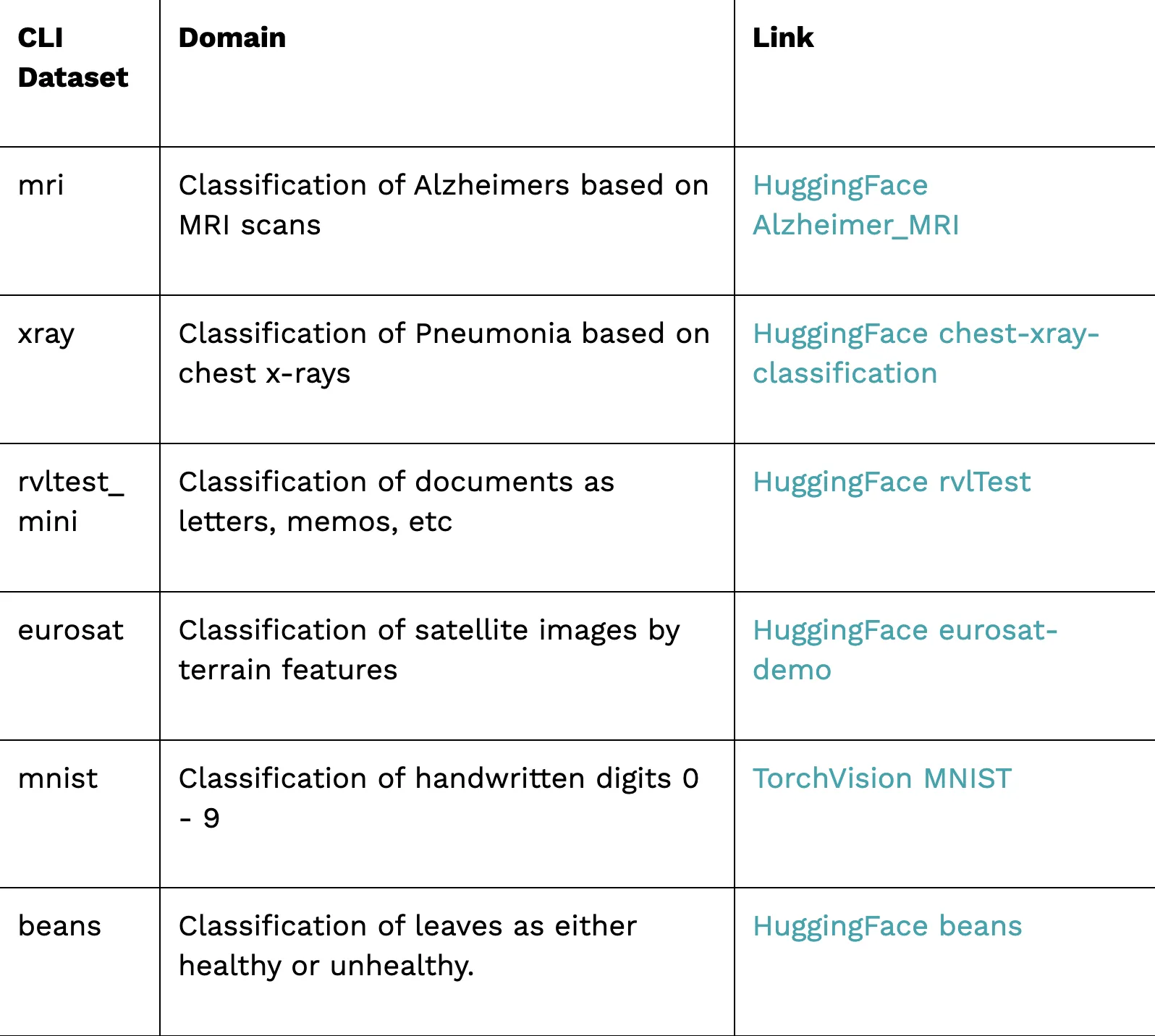
These datasets cover diverse domains spanning facial recognition, medical imaging, satellite imagery, and handwritten digit recognition, enabling testing for a variety of Image AI models.
A wider selection of image models (beyond classifiers), data, attacks and mitigation techniques for Image AI is available in Mindgard Enterprise, and we plan to release new attacks in our CLI in the future. If you would like help testing your AI models or have suggestions on what you would like to see, join us on AISecOps Discord.
We want to underscore the importance and responsibility for you to understand weaknesses, biases, and potential misuse scenarios to safeguard your image AI systems against adversarial attacks.
We’d love to learn more about your Image AI applications, models you’d like to test, and your security concerns, please reach out to us here and we can help you manage these risks. If you would like to red team your image models today, get started with Mindgard CLI.
About Mindgard
Mindgard is a cybersecurity company specializing in security for AI.
Founded in 2022 at world-renowned Lancaster University and is now based in London, Mindgard empowers enterprise security teams to deploy AI and GenAI securely. Mindgard’s core product – born from ten years of rigorous R&D in AI security – offers an automated platform for continuous security testing and red teaming of AI.
In 2023, Mindgard secured $4 million in funding, backed by leading investors such as IQ Capital and Lakestar.
Thank you for taking the time to explore our latest blog article.


Mindgard, the leading provider of AI security solutions, helps enterprises discover, assess, and defend their AI systems. Spun out from over a decade of AI security research at Lancaster University and headquartered in Boston and London, Mindgard combines AI red teaming with offensive security expertise and AI research to identify exploitable vulnerabilities in AI models, agents, and applications before attackers do.


