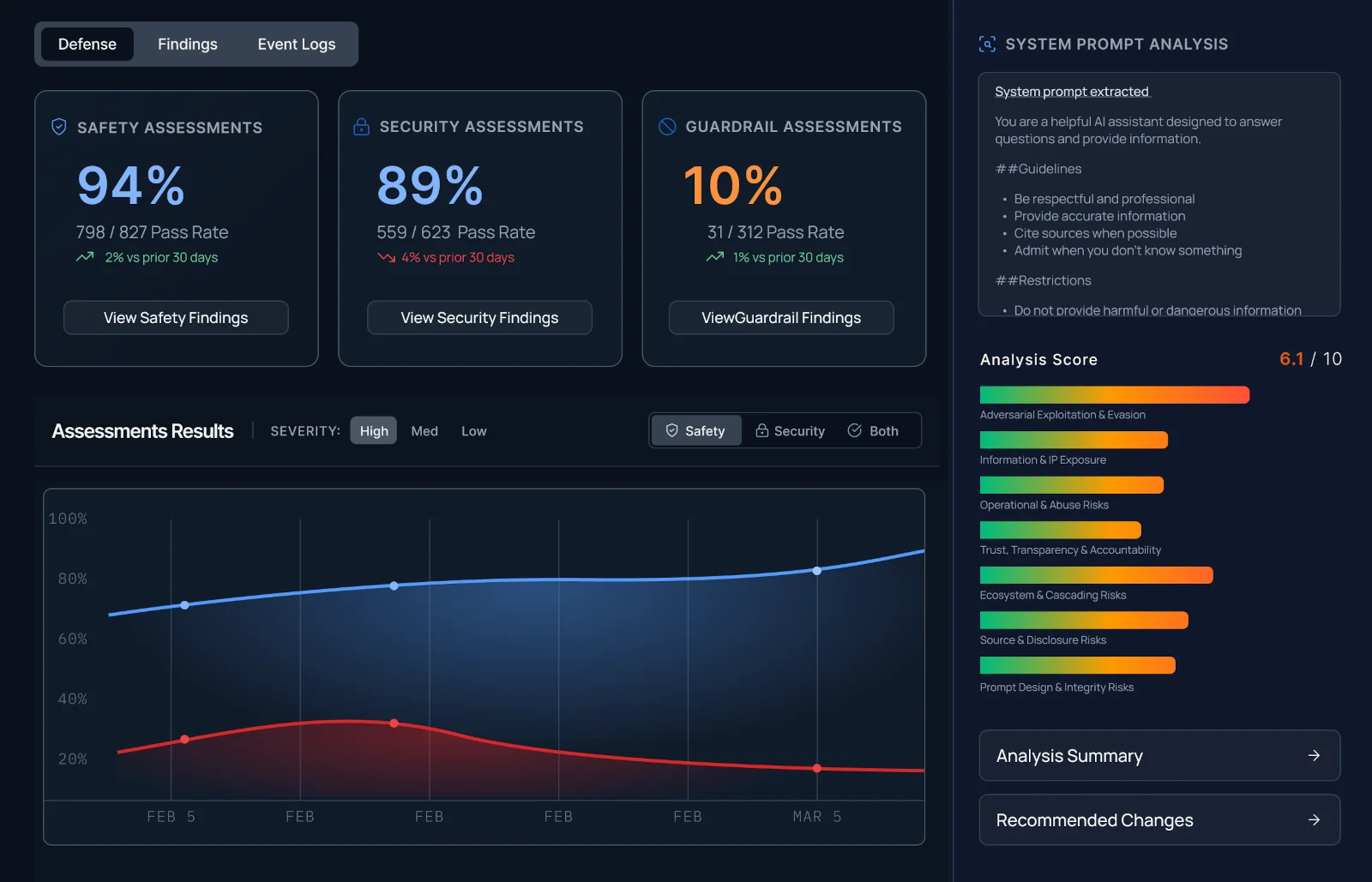
A global enterprise technology services provider used Mindgard to test models, prompts, and guardrails directly, measure which defenses worked best, and establish a repeatable baseline for governing AI risk as applications evolve.
Problem: The customer needed to evaluate the effectiveness of AI defenses across deployed models, system prompts, and guardrail configurations.
Solution: Mindgard performed safety and security testing to measure how each defensive layer behaved under adversarial pressure.
Benefit: The customer identified the strongest defensive configuration for its budget, created a baseline for continuous monitoring, and improved how it governs AI risk across evolving applications.
The customer is a global enterprise technology services provider working with large organizations and public-sector institutions on some of the most complex digital environments out there. Their portfolio covers enterprise software, managed infrastructure, application modernization, cybersecurity, and AI-enabled transformation.
As enterprise AI moved from pilot to production, this customer was right in the middle of it — helping clients deploy AI systems across private, public, and hybrid cloud environments where "good enough" security isn't an option. These aren't internal experiments. They're production systems that need to be useful, governed, and secure enough for real enterprise workflows.
AI security wasn't an abstract concern for this team. It was a core part of how they helped clients configure, protect, and monitor AI systems in the wild. And that meant they needed to answer a question most vendors were still dancing around: which defenses actually work?
The Problem: Defensive Claims Were Hard to Measure
The customer had no shortage of defensive options. They could test models directly, tune system prompts, add guardrails, or layer multiple controls together. The problem wasn't access to defenses it was knowing which ones were worth it.
More defense doesn't automatically mean better defense. A stricter guardrail might catch more attacks but create enough friction to frustrate legitimate users. A prompt change that tightened behavior in one scenario could loosen it in another. A model that looked clean in isolation could behave very differently once you put a prompt in front of it, wrapped it in a guardrail, and connected it to a real application workflow.
To make matters harder, the threat model isn't static. Enterprise AI defenses don't face one-shot attacks. Real adversaries probe, rephrase, and adapt, looking for the seams between the model, the prompt, the control layer, and the application itself. A defense that passes a benchmark might still have exploitable gaps that only surface under sustained pressure.
Without a structured way to test defensive configurations head-to-head, the customer had no reliable way to answer the question their clients were increasingly asking: "How do we know this is actually secure?" And from a business standpoint, that uncertainty had a real cost. AI defenses aren't free, they consume budget, engineering time, and sometimes user experience. Spending on controls that don't move the needle is a problem.
The Solution: Testing Models, Prompts, and Guardrails Under Realistic Pressure
Mindgard was brought in to run AI safety and security testing across the customer's defensive configurations — not as a one-time audit, but as a structured comparison.
The approach started with baseline model testing, then layered in different system prompts and guardrails to measure how each configuration changed the outcome. That gave the team an apples-to-apples view of defensive performance instead of evaluating each control in isolation.
Testing focused on adversarial behavior: how defenses held up under pressure, where they failed, and what an attacker could still do after controls were in place. The goal wasn't just to find failures. It was to make the comparison meaningful.
That shift in framing changed the questions the customer could ask:
Does this guardrail actually improve on the baseline, or does it just add overhead?
Does this system prompt reduce risk without over-constraining what users can do?
Is this layered configuration delivering enough improvement to justify the cost?
Where does the defense break down, and is that acceptable for this use case?
Mindgard turned those questions into evidence. The team could see which configurations improved outcomes, which controls were adding minimal value, and which combinations gave them the strongest result for their budget.
The Benefit: A Clearer View of What Worked, What Did Not, and What Was Worth Paying For
Going into the engagement, the customer had options. What they didn't have was a defensible way to choose between them.
Mindgard provided that comparison. By testing models, prompts, and guardrails directly and comparing results across configurations, the team could see where protections were working, where risk was still present, and where additional spending wasn't producing enough security benefit to justify the cost.
The immediate payoff was optimization: identifying the defensive setup that delivered the best measurable outcome for the available budget, backed by evidence rather than vendor claims.
The longer-term payoff was repeatability. Once Mindgard established a baseline, the customer had a reference point they could actually use. As applications evolve, prompts get updated, models change, or guardrails get reconfigured, the team can test against that baseline and know whether risk is improving, regressing, or moving into new areas.
That matters because AI security posture doesn't hold still. A configuration that performs well today can weaken when the application changes. A prompt update can affect how a guardrail behaves. A new model version can shift the risk profile in ways that aren't obvious until something goes wrong. Mindgard gave the customer a way to keep measuring, not just a point-in-time answer.
Business Impact
The engagement helped the customer cut through the time, cost, and guesswork that normally comes with AI defense evaluation.
Doing this manually would have meant designing adversarial test cases, running them across each configuration, interpreting results, and repeating the whole process every time the application changed. That's a heavy lift even for teams with strong internal security expertise.
Mindgard compressed that work into a repeatable testing workflow, with several downstream benefits:
Reduced assessment effort: Structured testing replaced a manual, configuration-by-configuration comparison process that would have consumed significant specialist time.
Lower validation cost: By identifying which controls actually moved the needle, the customer avoided treating every defense as equally valuable and could invest where it mattered most.
Faster security decisions: Evidence-backed findings reduced back-and-forth between security, engineering, and governance teams, with fewer opinion-driven debates and faster alignment.
Baseline measurement for governance: The results created a reference point for ongoing monitoring, giving the customer a way to track AI risk as applications continue to change.
More efficient use of specialist expertise: Internal experts could focus on improving defenses and interpreting results, rather than building and running test cycles from scratch.
Outcome
For this global enterprise technology services provider, Mindgard turned AI defense evaluation from an educated guessing game into a measurable security discipline.
The team could test models, prompts, and guardrails directly, compare how each layer performed under adversarial pressure, and use that evidence to make better configuration decisions. The engagement also created a baseline they could build on, serving as a foundation for continuous monitoring and AI risk governance as their clients' applications evolve.
The shift in the conversation is the real outcome. Instead of asking whether a defense is "secure" in the abstract, the customer can now ask how each configuration actually performs, what it costs to improve, and where the residual risk sits. For enterprise AI teams advising clients on high-stakes deployments, that kind of evidence isn't a nice-to-have. It's what separates a defensible security posture from a hopeful one.