


In This Article
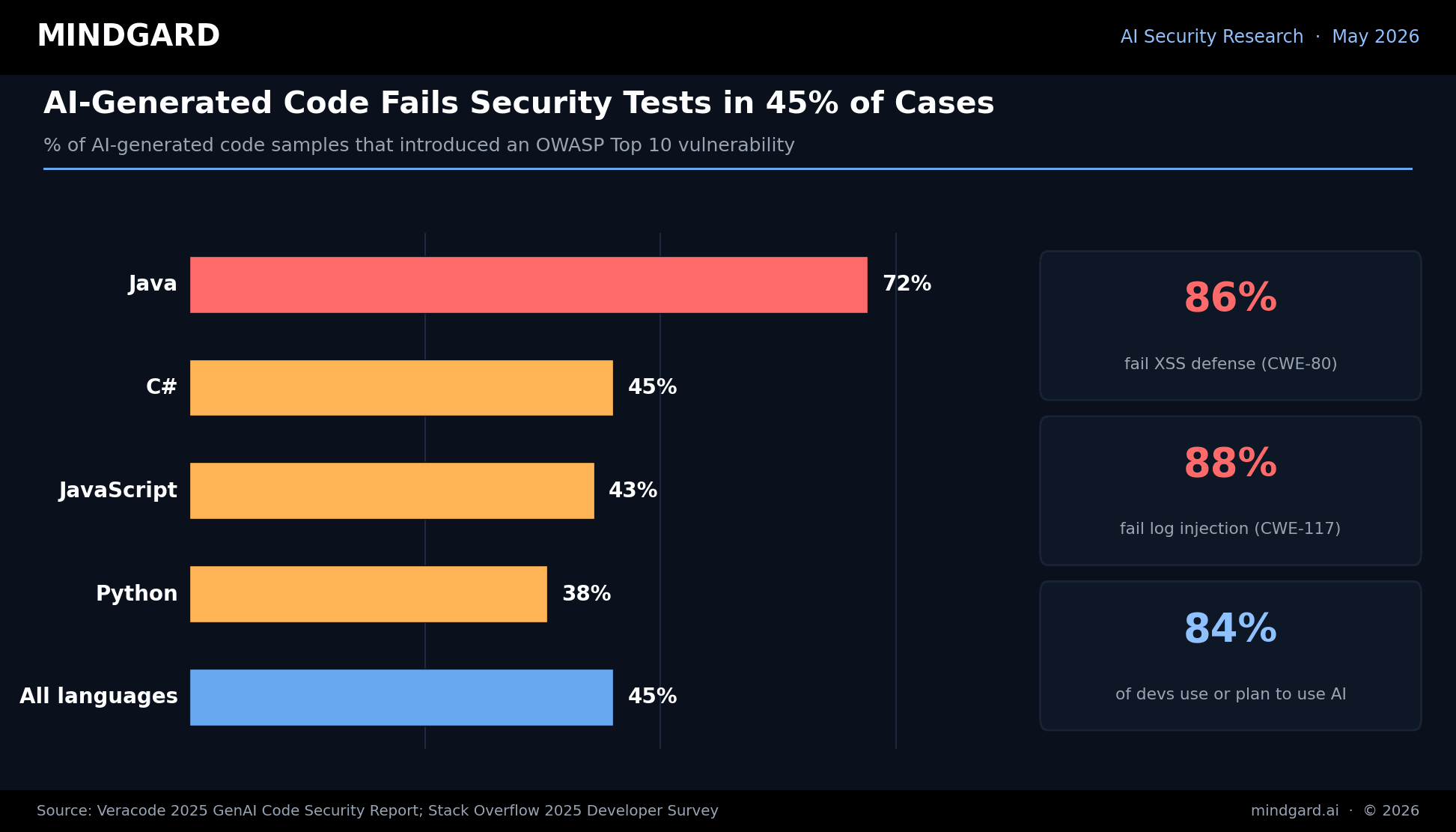
AI code security is the discipline of protecting software when AI coding assistants and LLMs are writing the code. The risk is measurable: Veracode's 2025 GenAI Code Security Report found that 45% of AI-generated code samples introduced an OWASP Top 10 vulnerability, including insecure dependencies, missing input validation, hardcoded secrets, prompt injection and supply chain flaws.
Eighty-four percent of developers now use or plan to use AI tools to write code, and 51% of professionals reach for them daily (Stack Overflow, 2025). Trust in those tools has fallen from over 70% in 2024 to 60% in 2025 as security incidents pile up.
Organizations have to treat every AI-generated snippet as untrusted, with automated SAST/SCA scanning, AI red teaming and human-in-the-loop review before any AI code reaches production.
This guide is the 2026 reference for AI code security. It covers the OWASP Top 10 for LLMs as it applies to AI-generated code, the five categories of AI code security risk (insecure output, supply chain, IP leakage, business logic flaws, model poisoning), the modern attacks every team should know (slopsquatting, MCP misconfiguration) and the controls engineering and security teams ship to keep AI-generated code secure.
AI Code Security Chart
Here's a look at the AI-generated code security failure rates by programming language:
- Java 72%
- C# 45%
- JavaScript 43%
- Python 38%
- All languages 45%
Source: Veracode 2025 GenAI Code Security Report
AI Code Risk Lookup for LLM Applications
We've created the interactive lookup below, which maps the OWASP Top 10 for LLM Applications 2025 to what each risk looks like in AI-generated code, with a one-line mitigation per entry.
Filter by category, sort by severity, or search by name to easily find risks that apply to your tech stack.
Five Categories of AI Code Security Risk
Before we walk through the OWASP Top 10 list of specific vulnerabilities, it's important to step back and group the AI code risks into the five high-level categories, which helps shape how engineering and security teams build their AI code governance program. These themes cut across the OWASP technical entries below and across the 2026-specific attacks (like slopsquatting, MCP misconfiguration), which are covered later in greater detail.
Think of these five categories as how you should think about the problem, while the OWASP Top 10 that follows is how to operationalize your team's response.
1. Insecure Code
While AI-generated code might appear polished, Veracode's 2025 analysis highlighted that LLM-produced Java code exhibited security flaws in over 70% of cases, with Python, C#, and JavaScript following at 38%-45%.
Veracode discovered that 86% of AI-generated code samples they tested failed to mitigate cross-site scripting (CWE-80) and 88% suffered from log injection problems (CWE-117). Both types of vulnerabilities read grammatically correct, which allows them to slip past human validation. What agents generate seems indistinguishable from code written by actual developers.

Hanqing Zhao, a graduate research assistant at Georgia Tech and lead researcher on one of 2025’s most-discussed vibe-coding security benchmarks explained bluntly:
"The vulnerabilities we found lead to breaches. Everyone is using these tools now. We need a feedback loop to identify which tools, which patterns, and which workflows create the most risk."
Based on their research, only 10.5% of solutions produced by agents were secure and functional, even when using state of the art LLM technology.
What does this mean for engineering teams? Don’t trust AI-created lines of code. Review them with someone knowledgeable in how these agents fail and scan them with an SAST/SCA pipeline tuned to spot common AI code flaws. This is a different breed of scanner, not the one you've been employing for a decade on human-written code.
2. Quality Issues
AI-generated code often comes with unintended bugs, performance issues and architectural problems that impact long-term code maintainability. Something that may work today will need significant rework tomorrow.
Gartner estimates prompt-to-app creations and “vibe coding” produced by citizen developers will be responsible for a 2,500% increase in software defects by 2028. The resulting rework will be felt directly by engineering teams.
The more significant issue is that AI-based programming assistants simply do not know how your application works, what it needs and any relevant laws. It can write working pieces of code but they do not satisfy specific domain regulations, particularly important when we speak of critical sectors such as medicine or banking. A piece of code that will compile successfully in a HIPAA-regulated system does not mean HIPAA compliance.
3. Legal Risks

Most machine learning tools learn from data publicly sourced from the web, which includes GitHub, StackOverflow, and proprietary code repositories. As such they can regurgitate sections of code that are similar or identical to protected works. There are already two lawsuits targeting organizations using generated code in this way: OpenAI v. New York Times and the Github Copilot lawsuit provide concrete examples of how these legal disputes have taken shape.
Simply having these codeblocks present in your system can expose you to copyright/liability issues, whether you intended to or not. You need to be extra careful if you work in a regulated industry or manage valuable IP assets. The shortcut you thought would make your life easier will end up being an expensive mistake requiring you to change everything.
Guideline: if an automatically generated chunk of code is longer than several lines and is not clearly needed for your project purposes, treat it as a risk of license attribution until you have proved otherwise. Run it through a license-scanning tool or, if available, the ML model's own "code referencing" utility to see if it matches any known protected works.
4. Intellectual Property Leakage
Most AI coding assistants train on users’ prompts/completions by default. Samsung’s 2023 disclosure of internal source code through ChatGPT stands out as a prime example, leading to a company-wide ban on consumer-facing LLMs in its semiconductor sector.
Deploying AI models that have been exposed to your proprietary/internal source code presents a significant risk of data exfiltration. That exposure may have no hard limit on what is stored/copied. Worse yet, your input may go toward training a public or third-party model. That means someone outside your organization (perhaps a malicious attacker) can pull up your company’s internal logic, trade secrets, or private designs. (Read our primer on AI data security for context on where these controls fit into your overall AI controls program.)
Implementing these 3 controls will help prevent AI data leakage:
- Select AI coding assistants that are enterprise-grade with a contractual promise not to train on customer data, as well as providing audit logs.
- Require IDE plugins to redact secrets and PII prior to leaving the developer workstation.
- Restrict access to consumer generative AI tools for employees working on sensitive code.
5. Loss of Human Skill

Daniel Kang is a professor of computer science at the University of Illinois Urbana-Champaign whose research focuses on AI coding security. In 2025, Kang warned:
"Even if you assume that the rate of security vulnerabilities in any given chunk of code is constant, the number of vulnerabilities will go up dramatically because people who don't know the first thing about computer security, and even experienced programmers who don't treat security as a top priority, are going to be producing more code."
Part of what Kang is saying is that AI coding applications increase the number of people who are shipping code. Those people have varying levels of security training and experience.
He's also suggesting that developers who blindly trust AI-generated code will gradually become less proficient with the systems they're working on. Over time, they become less familiar with the internals of the systems they build. Skills atrophy, and debugging, refactoring, and incident response are more difficult as a result.
To make matters worse, an AI tool can create a false sense of confidence. Developers who copy-paste AI output without understanding it aren’t exercising sufficient oversight, and subtle bugs or vulnerabilities can go undetected. Prevention is partly cultural: developers need a code-review mindset that treats AI-generated code like it was drafted by a junior engineer.
The OWASP Top 10 for LLMs (Critical AI-Coding Risks)
The five risk categories above form the big picture. To solve this problem, security teams need an actionable framework. That’s where the OWASP Top 10 for LLM Applications 2025 comes in. It’s the crib sheet security engineers should be flipping before giving any AI coding workflow their stamp of approval.
The lookup tool above connects each of the ten OWASP risks (LLM01–LLM10) with precisely what can go wrong with AI-generated code, along with a one-sentence explanation of how engineers can mitigate the risk before shipping. The five most critical risks for AI coding are:
- LLM01: Prompt Injection Attacks. Comments, READMEs or third-party libraries that the AI assistant reads can be specially crafted to alter its behavior. Results include backdoors, secret exfiltration commands or insecure defaults developers didn’t intend to introduce. (We maintain a list of known attack patterns in prompt injection techniques.)
- LLM03: Software Supply Chain Attacks. AI assistants commonly name or suggest fictional (“slopsquatted”) packages and import packages from malicious third-party libraries. (We explain this in greater detail below.)
- LLM05: Improper Output Handling. Handled input that’s concatenated to create SQL queries, shell commands, file paths or HTML markup can slip through code reviews because it “looks OK.” When executed, the concatenated output can introduce injection attacks.
- LLM06: Excessive Agency. AI coding assistants that have access to git, npm, and your shell can rewrite, push, and deploy code at scale. A single mistake can erase commit history or dump credentials.
Use this cheat sheet however works best for your team. But if you only do one thing after reading this article: select the OWASP for LLMs list, go through it line by line with your current AI coding workflow and note which mitigations you have in place and which you don’t. We built the interactive embed above for writers, security leads, and engineers to do just that.
Slopsquatting and Dependency Hallucination
In 2025 we discovered another class of supply-chain attack popularized to mainstream usage: slopsquatting. By researching various LLM coding assistants, we observed LLMs confidently suggest NPM and PyPI packages that do not actually exist, choosing names that seem plausible (fastify-cache, react-spinner-utils), but don't actually resolve to packages. Attackers register those names as real packages, upload malicious code, and sit back waiting for developers to copy-paste that AI-generated suggestion directly into their package.json.
How it works:
- Developer asks AI for package to do X.
- AI hallucinates believable package name.
- Attacker sees newly-misspelled package get created and registers it.
- Next developer to ask for X imports malware because the hallucinated name is now real.
Mitigations against dependency confusion recommended in 2026: pin every dependency, run SCA (supply chain analysis) on every package suggested by AI tools (not just the ones your developers remember to flag), block any package without X weeks of public existence and verifiable maintainer history at install time.
Securing the Tools Your AI Coding Assistant Connects To (MCP)
The difference between 2025 AI coding horror stories and present-day AI coding tools is agency. Contemporary code assistants aren't merely suggesting code inside editors; they're able to interface with actual services by way of Anthropic's Model Context Protocol (MCP) and perform read/write file operations, call APIs, submit pull requests, and run shell commands.
Which, of course, makes that ability a security risk. Any MCP server available to be used by AI coding assistants is a prompt-injection vector, and also somewhere where the assistant might have the capability to exfiltrate data. And what could be better as an implantation target for prompt-injections than a MCP server set up for a "community" task like "searching your entire repository?"
Three essentials for securing code-through-MCP:
- Explicit allowlisting, never auto-config. Only turn on MCP servers your security team explicitly approves. The “default registry” is not a trusted boundary.
- Scope tokens narrowly. If your MCP server allows assistants to read files, there’s no reason it should also have write or network scopes. Default to read-only; require human approval for destructive or outbound network actions.
- Log all tool calls. Agent code in a feedback loop can make thousands of tool calls per prompt. You need an audit log to spot unusual patterns, and crucially, to research after a breach.
The bottom line: AI red teaming your code assistant before deployment now has to cover the assistant plus the MCP servers it’s communicating with, end to end. Any tests that don’t account for the deployed model talking to other systems is ignoring where most of the new risk surface area will arise.
Comparing AI Code Security Tools
AI code security vendors have been racing to keep up with demand. By 2026, there were four fundamental buyer questions that separated standout tools from repurposed SAST:
- Does it allow you to test the AI assistant as well as the code it writes? Adversarial probing of the assistant for prompt injection, sensitive data leaks and supply-chain failure modes (a.k.a. AI red teaming) is required to truly test for OWASP LLM01–LLM10. Models that only scan generated output but never test the underlying model are looking at the problem from the wrong end of the telescope.
- Does it scan MCP servers and workflows that use agents? Without the ability to understand and model multi-step agent use cases, a tool will miss LLM06 (Excessive Agency) risks.
- Does it offer continuous monitoring, or just snapshot scanning? AI agents update silently in the background. If a model was safe last quarter it can easily become vulnerable this quarter. Continuous testing is significantly more important in AI than in traditional AppSec.
- Does it map results to the OWASP Top 10 for LLMs? Having your results mapped to a widely-accepted framework is critical for compliance, executive reporting and even consistent triage. (Gartner has its own parallel framework called AI TRiSM. It’s also useful to understand; we cover it in our Gartner AI TRiSM market guide).
You can find vendor-by-vendor comparisons in our guide to the best AI security tools for LLMs and GenAI, and in our list of best AI security companies. Here at Mindgard, our AI Security Platform was built from the ground up to answer those four questions. The best place for any team to start is by comparing at least two vendors against the OWASP for LLMs categories, and choosing the vendor that integrates best with your existing stack.
Best Practices Checklist for AI-Assisted Development
What does a AI coding security program look like for 2026? Check the boxes you’ve done and choose the next practice to implement.
- Signed policy on tool usage. Developers sign-off on acceptable tools and usage policy, where AI generated code can/cannot be used and merge review gates.
- Required human review. No AI generated code snippets are allowed to merge without a human reviewer with training on AI-specific failure modes: insecure defaults, license compliance risk, hallucinated dependencies and prompt injection flaws.
- AI-hardened SAST & SCA scanners. Off-the-shelf scanners can identify some issues, but lack intelligence around AI-developer behavior patterns. Include rulesets that are curated/tuned to AI-generated code and dependency slopsquatting attacks. Augment with AI guardrails around the runtime boundary of any process which invokes an LLM.
- Enterprise-grade AI tooling with “no-training” clauses. Block use of consumer tools from running on organizational endpoints.
- Secrets and PII scanning/block at the IDE. If it leaves your developer’s computer, it MUST be scrubbed.
- Pinned dependencies + maintainer-history validation. Prevent installation of packages without N weeks of public history and confirmed maintainer history.
- Scoped agent access tokens. These tokens should default to read-only and require human approval prior to write, destroy, or connect-to-network tasks. Each task is its own token and has tool-call limits.
- OWASP for LLMs risk mapping. Run through the 10 risks against your current environment quarterly. Track mitigations and gaps.
- Your AI assistants and MCP servers are now production systems. Treat them as such. Don’t deploy code or ship agents until they’ve been tested. There’s no grade inflation in production. Maintain the same testing rigor for AI output as you do for code. Use our red teaming checklist for an initial assessment.
- Logging and alerting on all AI activity. From prompts sent to tooling calls to PRs opened by agents, know what your AI resources are doing and take action when policies are violated.
Enjoy Productivity Without Paranoia
AI-assisted coding isn’t new. It’s already the standard authoring tool for 50% of engineers.
We can’t prohibit its use. For security leaders, the question is not if they can use it, but how to secure what it creates.
Andrej Karpathy, the influential AI researcher who popularized the phrase “vibe coding,” put it best. Earlier this year he cautioned that agents would “just generate slop” if people stopped reviewing them (source).
Once engineers start writing with AI, the bulk of the developer’s work moves from coding to reviewing. The rigor we once applied to a junior engineer’s first draft must now be applied to every AI recommendation, multiplied many times over.
the tools and techniques that enable teams to effectively secure AI-generated code in 2026 are the same ones that have worked for decades with human-generated code, applied judiciously and at AI-speed. Policy, pre-commit review, AI-capable AppSec tools, least privilege agent access and continuous testing.
Mindgard’s Offensive Security for AI helps security teams stay ahead of these risks by providing powerful AI threat modeling, red teaming, and continuous monitoring tools specifically designed for AI-driven environments. Book a Mindgard demo now to safeguard your AI systems.
Frequently Asked Questions
Will AI-generated code survive traditional code reviews?
Maybe. Some problems in AI-written code look obvious after the fact, but aren't caught by reviewers without AI-specific training. These include invisible problems, like insecure defaults and logic so opaque it can’t be reviewed, and magical thinking mistakes like hallucinated dependencies and prompt-injection-via-comment.
What’s the safest way for teams to start using AI coding tools?
With homework. Documentation around your company’s usage policy should require human reviewers for all AI-generated code, prohibit AI coding tool use in high-risk systems and put AI context into your automated security scanners.
Pair AI coding tools with code linters, dependency trackers, scoped agent tokens and a secure SDLC. The 10-step checklist above is the short version.
Should AI-generated code be treated differently during audits or security assessments?
Absolutely. When conducting security assessments, items flagged as AI-assisted should be scoped for review for proper licensing, dependency hallucination, structural vulnerabilities and OWASP Top 10 for LLMs vectors and reviewed separately. Requiring code authors to log the use of AI enables this sort of inspection.
What is the OWASP Top 10 for LLMs and why does it matter for AI-generated code?
The OWASP Top 10 for LLM Applications 2025 is the standard framework for the top vulnerabilities in LLM-powered systems, including coding assistants. It covers prompt injection, sensitive information disclosure, supply chain, data and model poisoning, improper output handling, excessive agency, system prompt leakage, vector and embedding weaknesses, misinformation and unbounded consumption. It's the right checklist for AI coding security, not the generic application-security checklist.
What is slopsquatting and is it a real threat?
Slopsquatting refers to the registration and publishing of malicious packages that AI coding assistants hallucinate. First reported as being mainstream in 2025 as a supply-chain attack vector, it bypasses traditional Software Composition Analysis (SCA) because the malicious package “exists”. As such dependency pinning plus maintainer history validation are required as a matter of best practice.
Should AI-generated code be allowed into production?
With appropriate controls in place. Veracode Labs tests in 2025 revealed that 45% of AI-generated code snippets contained an OWASP Top 10 vulnerability.
Requiring human review, using AI-aware SAST/SCA, utilizing scoped agent tokens and continuous AI red teaming will allow you to realize the productivity gain without increasing your breach risk. Absent those controls, allowing AI-generated code into production should be considered a known unsafe configuration.

