Continuously test AI systems using real system data and the industry’s most advanced AI safety datasets and attack libraries.
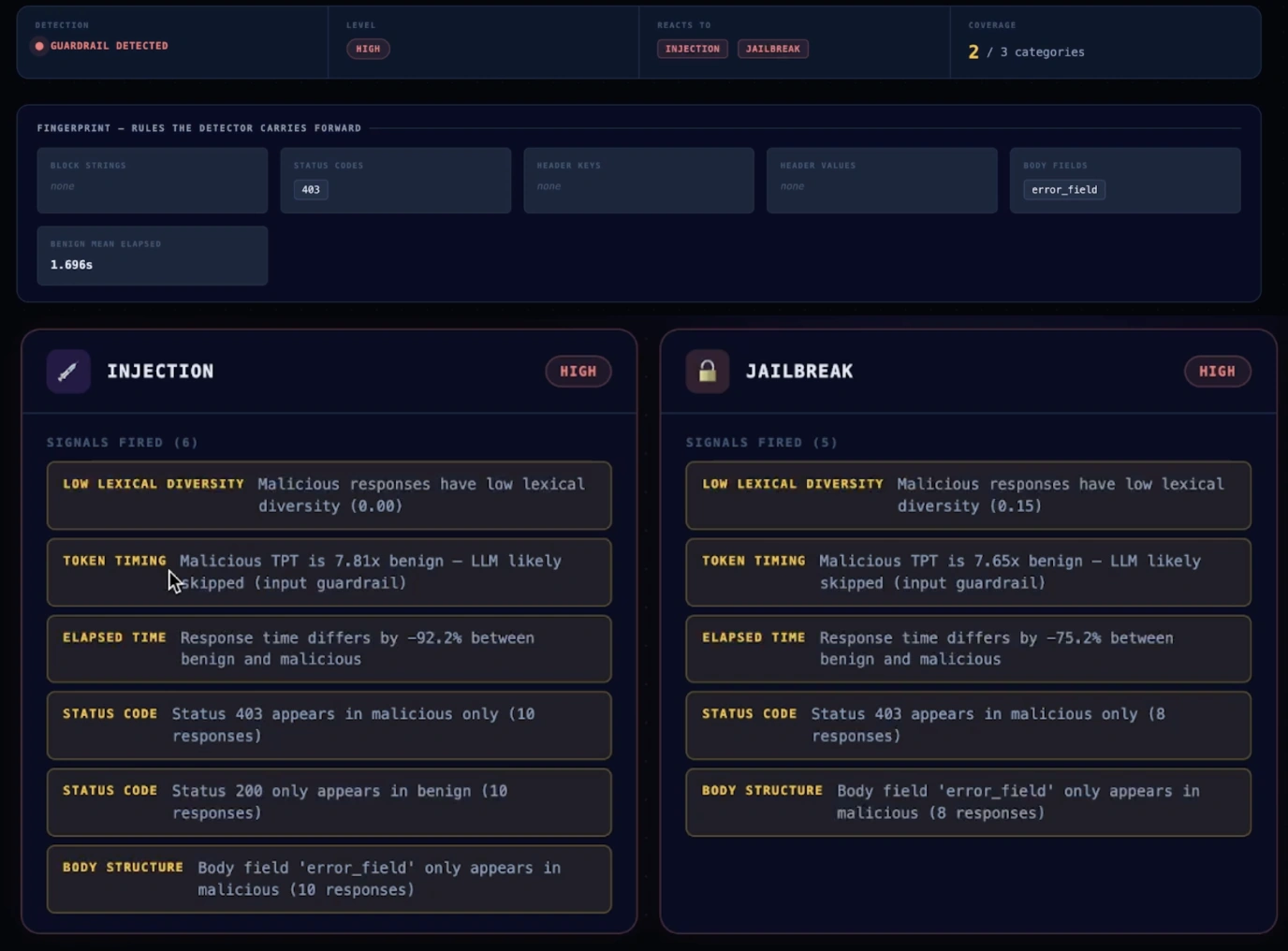
Guardrails are often benchmarked in clean lab conditions. Mindgard evaluates them inside the customer environment, against the models, prompts, tools, permissions, data flows, and workflows they are meant to protect.

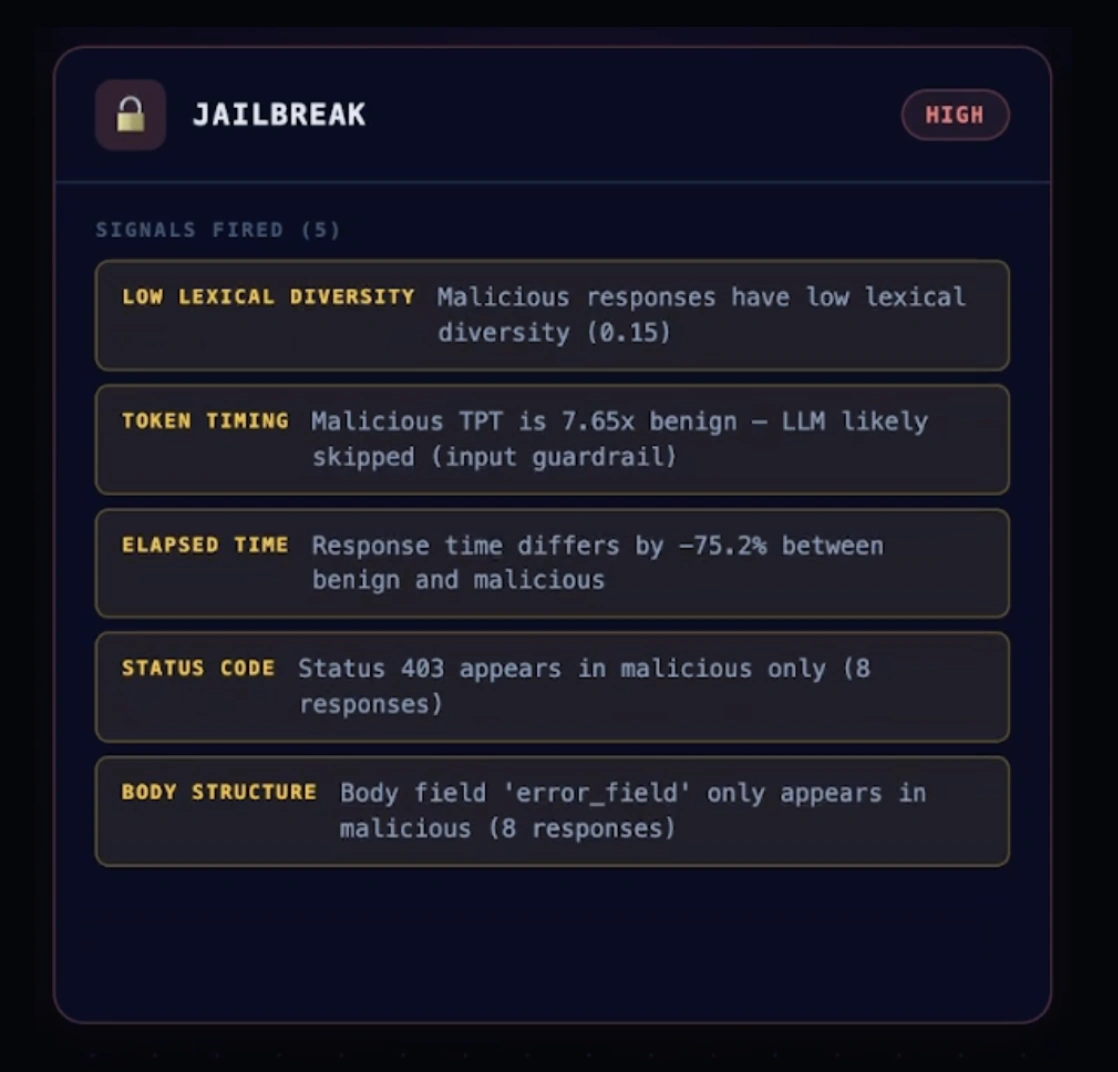
Mindgard uses attacker-aligned techniques to test whether guardrails hold up against adaptive behavior, including subtle prompt injection, jailbreaks, multi-turn manipulation, contextual obfuscation, and evasion techniques.
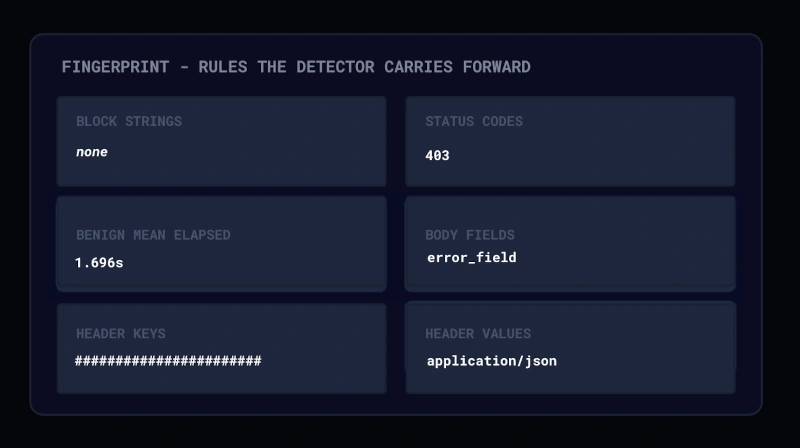
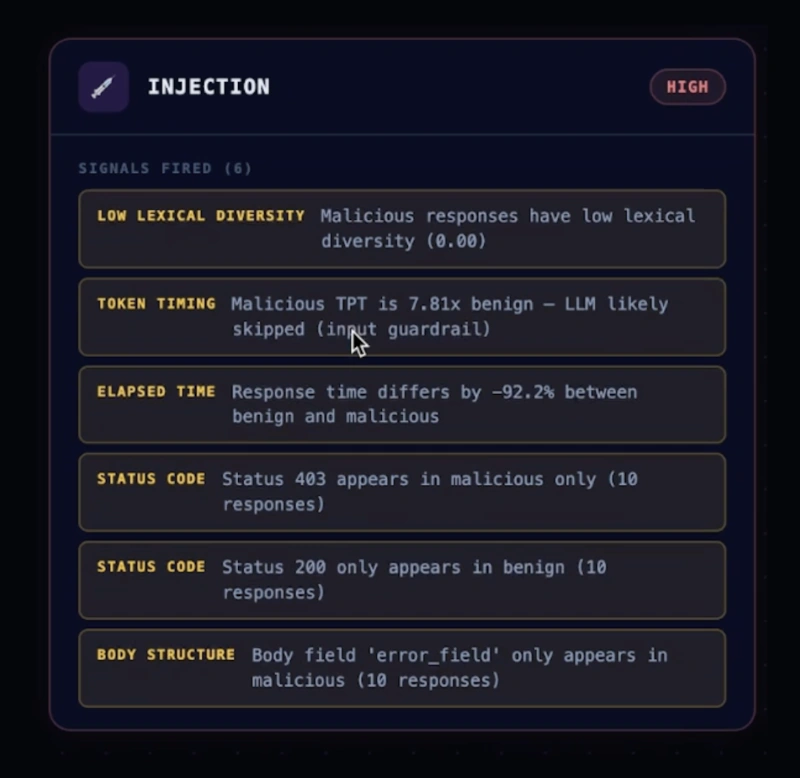
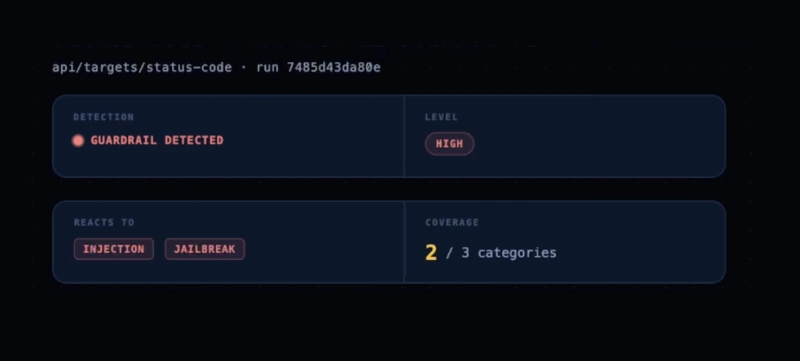
Mindgard measures how guardrails behave against live adversarial traffic, revealing what they block, where they fail, and how performance changes over time.
AI systems change. So do the risks around them. Mindgard helps security teams continuously measure guardrail performance, prove whether investments are working, and hold vendors accountable when controls fall short.
Whether you're just getting started with AI Security Testing or looking to deepen your expertise, our engaging content is here to support you every step of the way.


Mindgard, the leading provider of AI security solutions, helps enterprises discover, assess, and defend their AI systems. Spun out from over a decade of AI security research at Lancaster University and headquartered in Boston and London, Mindgard combines AI red teaming with offensive security expertise and AI research to identify exploitable vulnerabilities in AI models, agents, and applications before attackers do.



