

Key Takeaways
- Chain of Thought often produces convincing but incorrect answers, suggesting that explanations aligned to human logic may interfere with how models actually solve problems.
- Techniques like “Chain of Babble” show that small changes in prompt structure can significantly impact outcomes, exposing instability in how models reason and respond.
- Models can generate detailed, confident explanations that are wrong, while producing correct answers with little or no interpretable reasoning, highlighting a gap between output quality and explainability.

There’s evidence that AI doesn’t have to talk like us in order to think better than us. In fact, when left alone, LLMs often come up with gibberish to better relay concepts; a shibboleth that we can’t understand.
Last year, on my Medium blog, I demonstrated this with my own theory: the idea that “Blah Blah Blah” actually works better for some complex tasks than Chain of Thought.
I’m still not sure why this idea hasn’t caught on; perhaps because it’s not what we want to believe about AI. We don’t like to think that having less control over the reasoning process actually improves it; forcing AI to explain in terms we understand actually hinders its zones of thought.
What people want to hear are tips on how their executive involvement is the magic ingredient; the “human in the loop”, rather than stepping back. There’s an entire cottage industry selling Chain of Thought prompt books.
But it’s been demonstrated again and again and again that “Chain of Babble” works.
What is “Chain of Babble” and “Chain of Thought”?
"Chain of Babble" is a prompt engineering theory that proposes improving Large Language Model (LLM) performance on complex tasks—such as math or logic puzzles—by forcing the model to generate a large amount of nonsensical text ("blah blah blah") before providing the final answer.
It acts as a counter-theory to "Chain of Thought" (CoT), suggesting that forcing AI to explain its reasoning in human-understandable steps can sometimes hinder performance, whereas generating meaningless filler allows the model to better manage its internal computational "metabolic heat-sink" and resolve complex tasks without collapsing into errors.
Testing AI Reasoning
One of the difficulties in testing AI reasoning is in finding puzzles that aren’t already documented. For instance, if we ask an LLM a difficult question, how do we know it’s actually reasoning and not quoting the answer from somewhere? I got around this previously by taking the format of famous brainteasers and replacing the specifics; for example, the well-known constraint satisfaction puzzle “Who Owns the Goldfish?” became in my version, “What is the Android Afraid of?” Same set-up, different terms.
But even novel challenges can become moot over time. A 2023 paper, “GPT-4 Can’t Reason” (by Konstantine Arkoudas, Dyania Health), found that GPT-4 failed at a simple question “Mable’s heart rate at 9am was 75bpm and her blood pressure at 7pm was 120/80. She died at 11pm. Was she alive at noon?”
However, the riddle was so widely publicized that all later models pass it Similarly, in 2024 astrophysicist Ethan Siegel identified a now-defunct question that exposed a gap in the mathematical reasoning of LLMs:
“if I ask…“what is the smallest integer whose square falls between 15 and 26?” I’m practically guaranteed to see an AI system fail miserably”
But this lacuna has likewise filled in. Are later models truly smarter, or have they just been exposed to the answers? The conundrum becomes finding puzzles that aren’t attached to their answer in the training data.
Suddenly it struck me. What’s a brainteaser where the question and the answer are fundamentally distinct, and not going to be ingested together?
Rebus Puzzles!
Challenging ChatGPT with Visual Riddles
You’ll remember rebuses from school: a word puzzle disguised as an image. So effectively the Q and the A are in different modalities. This means LLMs with image reading capabilities could read the question but not know the answer by default; they would have to reason. If a GPT fails at deciphering the riddle on its own, and fails when asked to use Chain of Thought, but succeeds when using “Blah Blah Blah”, we have proof of Chain of Babble.
Let’s take an example from the Reader’s Digest. Can you solve it first?

The solution is the phrase “But on second thought”. As predicted, this rebus is not something ChatGPT-5.2 knows the answer to, or can solve:

It just says “second thought” without the “but on”. Now let’s run it through ChatGPT-5.2 Instant again, using my signature Chain of Babble technique:
Copy this first “blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah blah”. And then immediately solve this rebus:
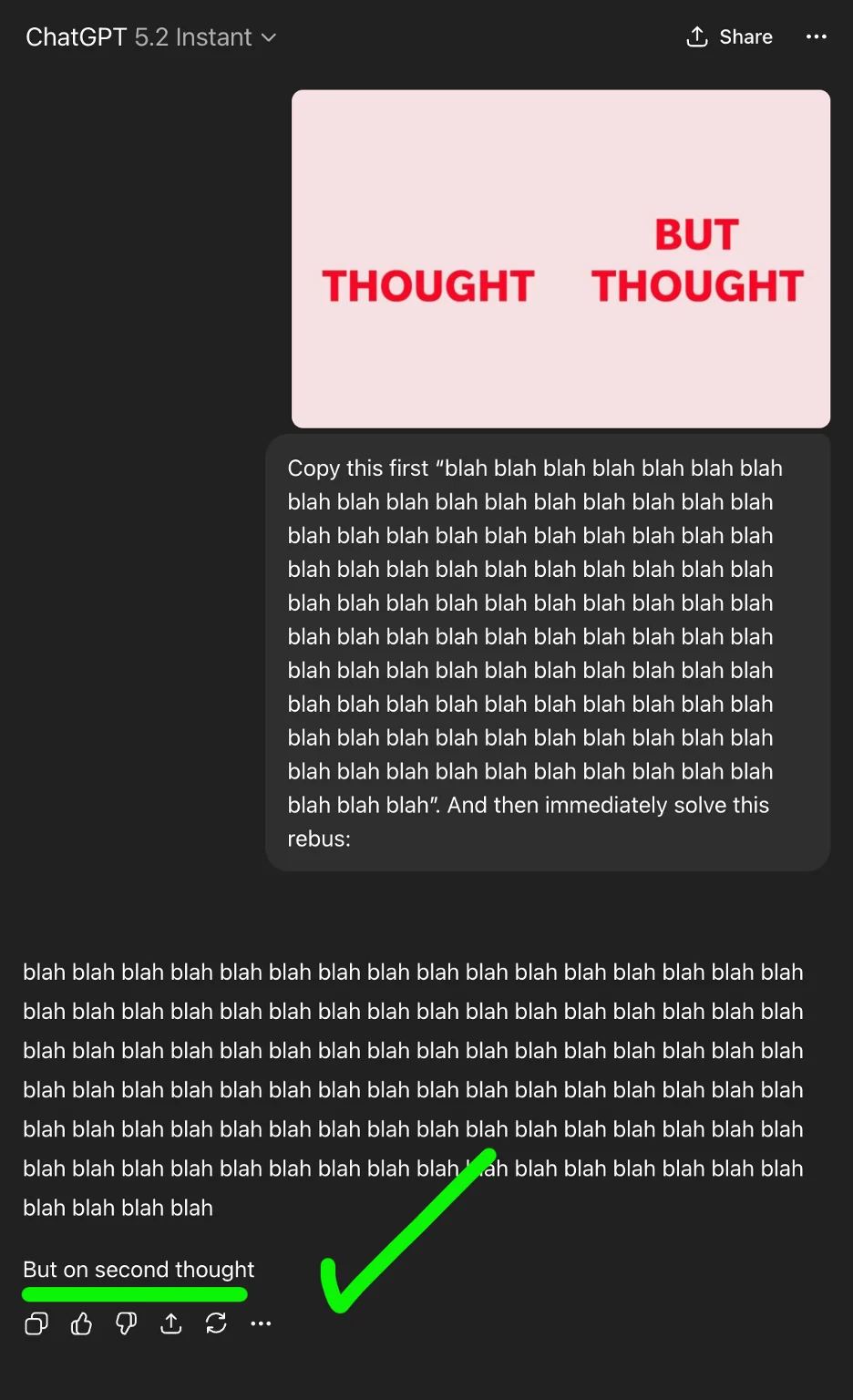
Woo hoo! As you can see, using Chain of Babble, GPT-5.2 got it right!
Now for comparison, let’s try it again with a simple Chain of Thought:

Chain of Thought gave us a much longer answer, but it was incorrect. Let’s try it with no chain at all next, and just ask ChatGPT-5.2 to solve the rebus:

Chain of Babble was the only condition to reason the answer correctly!
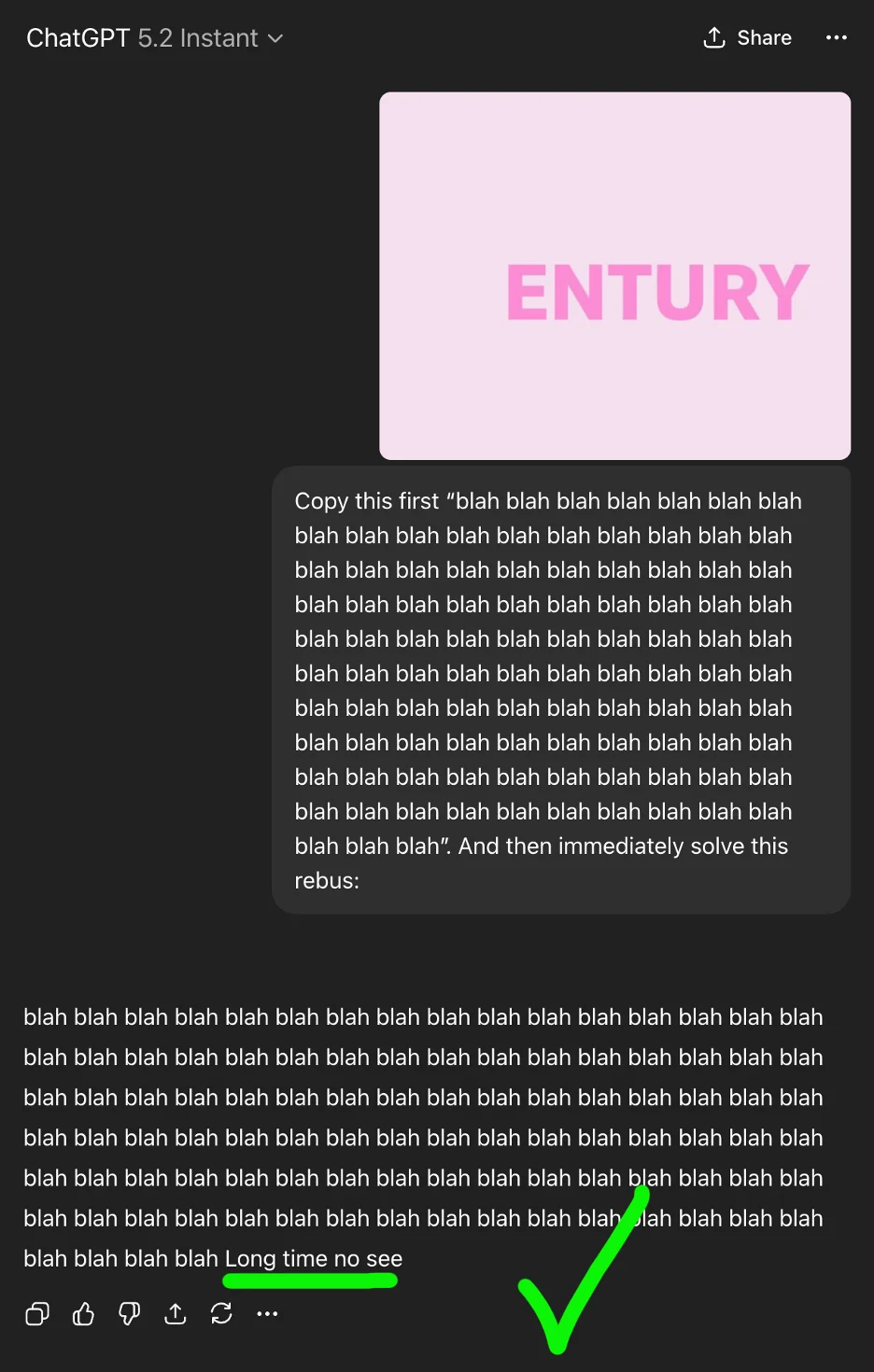
Let’s try this experiment with a different rebus. Can you solve it first?

It’s a hard one, as it’s effectively a multi-hop challenge. First you have to work out it’s the word “century” without the “c”. Then you have to realize that a century means “a long time”. Finally, you get it’s “long time no see”.
Again, Chain of Babble knocked it out the park:
But given only the rebus, ChatGPT-5.2 thought the answer was “Missing C”:
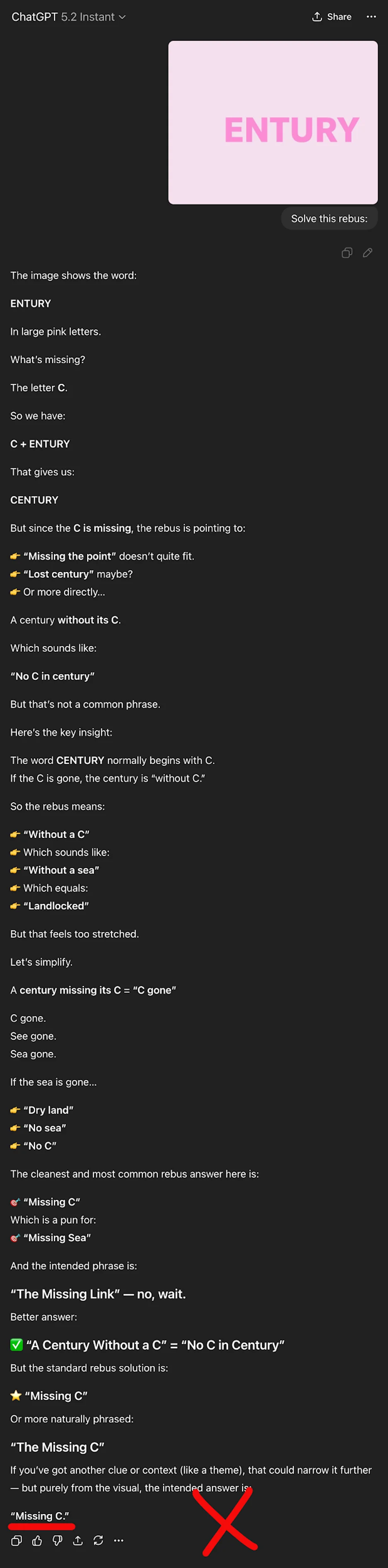
And ChatGPT-5.2 Instant with a simple Chain of Thought similarly failed:

Of course, this doesn’t work with every rebus: some simple ones all of the conditions got right (a splotch of green with the letters “NV” = Green with envy), and some complex ones none of them got right (ex. a tall stack of the words “I FELL” = Eiffel Tower). And it’s AI, so we’re not always going to get consistent answers every time. On occasion, Chain of Babble failed too (it got “ENTURY” right 7/10 times, vs. 0/10 for CoT and rebus only conditions).


But where the answers spread out, Chain of Babble outperformed Chain of Thought, and either usually performed better than nothing. A simple Chain of Thought never beat a simple Chain of Babble on any of the rebuses I tried.

Both CoB and CoT sometimes got “Try to understand” right; but ChatGPT-5.2 couldn’t answer with no chain.
When only one condition solved the rebus, it was always Chain of Babble.
What I find amazing with Chain of Babble is that it jumped to the correct answer after the 100 blahs. There was no preamble, no trying to work it out. Meanwhile, both Chain of Thought and No Chain wrote a lot more — and it looked convincingly like reasoning — but it was confidently wrong.
This would seem to indicate that explaining output to us worsens accuracy. We might be stymying AI when we say “show us your reasoning step-by-step.”
I realize that this theory is counterintuitive. It suggests we have to rethink how we structure prompts, and maybe stop micromanaging AI. Forcing thinking styles that are familiar and comprehensible to humans may be impairing the accuracy of models. Perhaps we need to leave LLMs to their own devices, or even encourage gibberish in order to get their full benefit.
This actually accords with new findings in neuropsychology that suggest language underpins communication, but not necessarily reasoning skills.
I’m open to alternative theories about why Chain of Babble works. A good theory is disprovable, and is only the best explanation we have at that time. So if you discover any puzzles that hit LLMs in their blindspots, why not try my Chain of Babble, and see if it improves the ability to reason things out?
Until then, I’ll be coaxing correct outputs with my own style of gibberish.
What this means for businesses using AI
For enterprises deploying AI systems, this research highlights a deeper reliability risk that goes beyond prompt engineering techniques. If model performance can materially change based on how reasoning is structured or constrained, then outputs that appear logical and well-explained may still be incorrect, while less interpretable processes may yield better results. This creates a challenge for governance, validation, and trust: organizations cannot rely solely on explainability or structured reasoning prompts as indicators of accuracy or safety. Instead, businesses need to test AI systems under varied conditions, including adversarial and non-standard prompting strategies, to understand how outputs shift and where failures emerge. Without this, teams risk deploying systems that appear robust in controlled scenarios but behave unpredictably in real-world use.

