
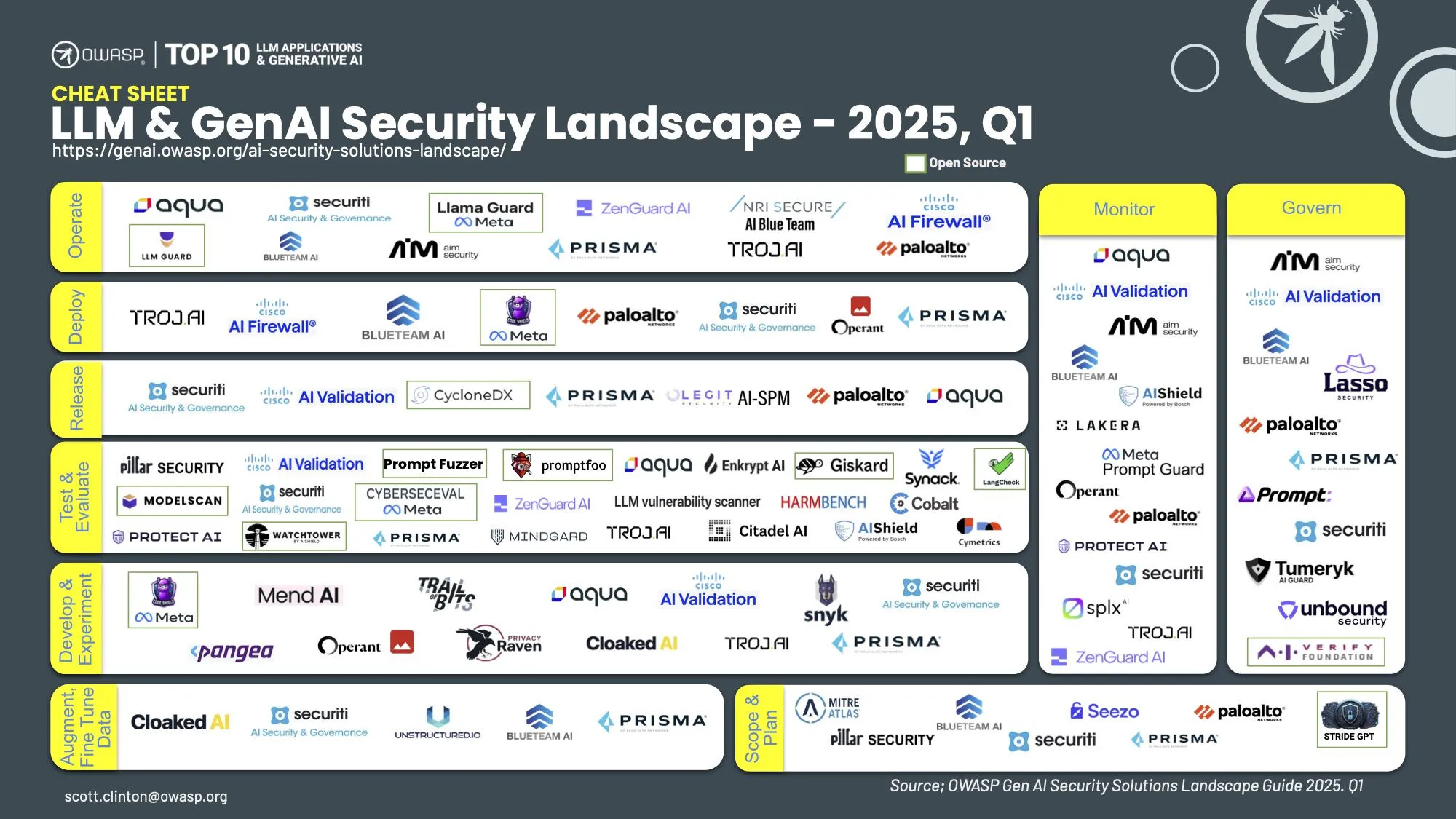

Key Takeaways
Mindgard has been featured in the OWASP’s Q1 2025 LLM and Generative AI Security Solutions Landscape for our expertise in:
- Adversarial Testing: Detecting and mitigating risks posed by malicious inputs that could compromise LLM behavior.
- Bias and Fairness Testing: Ensuring ethical, unbiased outputs from AI models.
- Vulnerability Scanning: Identifying weaknesses in model architecture and data pipelines.
- Secure Deployment Practices: Safeguarding models during the transition to production environments.
- Final Security Audit: A comprehensive evaluation conducted at the end of the development and testing phases, just before deploying the system into a production environment. Its goal is to ensure that the AI system meets all security, compliance, and operational requirements and that it is robust against known threats.
- LLM Benchmarking: Evaluate and compare the performance, efficiency, and security of large language models (LLMs) using standardized metrics, datasets, and scenarios.
- Penetration Testing: A proactive security practice where ethical hackers simulate real-world attacks on an AI system to identify vulnerabilities and weaknesses. The goal is to uncover and remediate security flaws that could be exploited by malicious actors, ensuring the AI system is robust, secure, and resilient against potential threats.
- SAST/DAST/IAST: Mindgard delivers the first and only Dynamic Application Security Testing for AI (DAST-AI) solution specifically designed to detect and remediate AI-specific vulnerabilities that only manifest during runtime.

We are thrilled to announce that Mindgard has been recognized in OWASP’s Q1 2025 LLM and Generative AI Security Solutions Landscape. This acknowledgment underscores our commitment to advancing security and safety for all types of AI, including large language models (LLMs) and generative AI applications.
The Open Worldwide Application Security Project (OWASP) is a nonprofit foundation that works to improve the security of software. The organization is one of the most trusted authorities in software security, and has long been a guiding force in enabling organizations to conceive, develop, acquire, operate, and maintain applications that can be trusted. OWASP’s inclusion of Mindgard in the LLM and Generative AI Security Solutions Landscape - Q1,2025, signals a growing recognition of the unique challenges AI and LLM-based technologies present and our capability to address them effectively.
The Importance of OWASP Recognition
Recognition by OWASP is a significant endorsement from one of the most respected organizations in the global cybersecurity community. OWASP is renowned for its commitment to providing practical, actionable guidance that helps organizations navigate the evolving landscape of application and data security. For over two decades, OWASP has set the benchmark for identifying and mitigating critical security risks. From their flagship Top 10 lists to detailed reference guides, OWASP has become the gold standard for organizations looking to adopt robust security practices.
Being featured in OWASP’s LLM and Generative AI Security Solutions Landscape is a testament to Mindgard’s credibility, innovation, and alignment with industry-leading best practices. OWASP’s LLM and Generative AI Security Solutions Landscape serves as a critical reference for developers, security leaders, and decision-makers aiming to build secure, trustworthy AI systems. This inclusion reflects Mindgard’s innovative approach to tackling the complex security challenges associated with generative AI, including adversarial attacks, data leakage, and ethical risks.
The OWASP Top 10 for LLM Applications
The OWASP Top 10 for Large Language Model (LLM) Applications is a set of the most critical risks associated with developing, deploying, and operating applications powered by large language models. The list aims to guide organizations in understanding and mitigating the unique security challenges posed by LLMs and generative AI systems. The OWASP Top 10 for LLM Applications 2025 is the latest understanding of existing risks and introduces critical updates on how LLMs are used in real-world applications.
LLM01:2025 Prompt Injection
Maliciously crafted inputs can manipulate the behavior of LLMs, leading to unintended or harmful outputs, including the leaking of sensitive data or execution of unauthorized commands.
LLM02:2025 Sensitive Information Disclosure
LLMs may inadvertently expose sensitive or private information due to flaws in how they are trained, fine-tuned, or prompted.
LLM03:2025 Supply Chain
LLM applications often integrate with external systems, APIs, or data sources, introducing vulnerabilities through these dependencies.
LLM04:2025 Data and Model Poisoning
Carefully crafted inputs can exploit vulnerabilities in the model, causing it to behave unpredictably or produce biased, offensive, or otherwise harmful outputs.
LLM05:2025 Improper Output Handling
Highlights the risks associated with large language models producing outputs that are unsafe, sensitive, or misleading. This includes challenges like unfiltered responses, data leakage, or outputs that violate compliance or ethical standards, emphasizing the need for robust validation, filtering, and security measures to manage model outputs effectively.
LLM06:2025 Excessive Agency
Weak authentication, insecure API endpoints, or inadequate access controls can allow attackers to misuse or exploit LLM-powered systems.
LLM07:2025 System Prompt Leakage
Refers to the unintentional exposure of system prompts or internal configurations embedded in large language model applications. This vulnerability can reveal sensitive logic, instructions, or operational data, enabling attackers to exploit the system or manipulate its behavior, underscoring the need for strict access controls and prompt isolation mechanisms.
LLM08:2025 Vector and Embedding Weaknesses
Addresses vulnerabilities in the representation of data as vectors or embeddings used by large language models. These weaknesses can be exploited to inject malicious data, manipulate model outputs, or infer sensitive information, highlighting the importance of securing embedding processes and implementing robust validation techniques.
LLM09:2025 Misinformation
LLM systems must align with legal and ethical standards, including privacy regulations (e.g., GDPR) and content moderation policies. Improper handling of training data can lead to data poisoning, unauthorized access, or legal and compliance issues related to intellectual property or privacy. LLMs can unintentionally perpetuate or amplify biases present in their training data, leading to outputs that may be unethical, discriminatory, or inappropriate. LLMs can produce outputs that appear credible but are factually inaccurate, misleading, or completely fabricated—referred to as "hallucinations."
LLM10:2025 Unbounded Consumption
Highlights the risks of resource exhaustion or performance degradation caused by unrestricted use of large language models. This issue arises from scenarios like excessive API calls, unregulated input sizes, or uncontrolled computation, emphasizing the need for rate limiting, input validation, and resource management to ensure system stability and security.
The OWASP Top 10 for LLM Applications provides a framework for AppSec professionals, DevSecOps and MLSecOps teams, data engineers, data scientists, CISOs, and security leaders who are focused on developing strategies to secure Large Language Models (LLMs) and Generative AI applications; equipping them with the knowledge and tools necessary to build robust, secure AI applications. As a trusted standard, the OWASP Top 10 is widely referenced in compliance frameworks and by security professionals globally. Beyond identifying risks, the list often links to recommended mitigations, tools, and best practices, helping organizations proactively address vulnerabilities.
What Sets Mindgard Apart?
Mindgard stands out for its comprehensive expertise and innovative solutions that address the unique security challenges of LLMs and generative AI applications. Our key strengths include:
- Adversarial Testing: Identifying and mitigating risks from malicious inputs to ensure LLMs remain secure and behave as intended.
- Bias and Fairness Testing: Delivering ethical and unbiased outputs by proactively analyzing and addressing model biases.
- Vulnerability Scanning: Detecting and resolving weaknesses in model architecture and data pipelines to strengthen security.
- Secure Deployment Practices: Safeguarding AI systems during deployment to ensure they remain protected in production environments.
- Final Security Audit: Performing a thorough evaluation at the conclusion of development and testing to ensure AI systems meet all security, compliance, and operational standards while being resilient against known threats.
- LLM Benchmarking: Evaluating and comparing LLM performance, efficiency, and security through standardized metrics and datasets.
- Penetration Testing: Simulating real-world attacks to uncover and resolve vulnerabilities, ensuring robust and resilient AI systems.
- SAST/DAST/IAST: Introducing the industry’s first Dynamic Application Security Testing for AI (DAST-AI) solution, specifically designed to identify and address AI-specific vulnerabilities that only appear during runtime.
Our comprehensive solution, covering LLM01, LLM02, LLM04, LLM05, LLM06, LLM07, LLM08, LLM09, and LLM10, tailored for every stage of the AI lifecycle—planning, deployment, operation, and monitoring—demonstrate our commitment to robust, ai security, and AI Red Teaming and pentesting.
To learn more about Mindgard’s solutions or to explore our coverage of the OWASP Top 10 for LLM Applications book a demo. Let’s work together to secure the future of AI.

